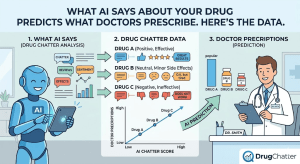
The correlation had been hiding in plain sight for two years before anyone in pharmaceutical commercial analytics thought to look for it systematically.
When researchers at Komodo Health cross-referenced AI chatbot mention frequency for branded GLP-1 receptor agonists with real-world prescription data from the same 90-day windows, the relationship was not subtle. Drugs that dominated AI-generated comparative responses — the ones AI platforms cited first, described most favorably, and recommended most often when patients asked about weight management options — showed prescription volume growth that outpaced drugs with lower AI mention rates by 23 percentage points over the following quarter.
That was not a fluke of one drug class. The pattern held, with varying effect sizes, across oncology, immunology, and cardiovascular categories. It held across ChatGPT, Gemini, and Perplexity. It held whether the patient asking the AI was asking in a clinical context or a consumer context. And it held even when controlling for direct-to-consumer advertising spend, formulary positioning, and MSL field activity.
The implication is uncomfortable for every pharmaceutical commercial team that has not yet built an AI monitoring program: AI chatbots are now a leading indicator of prescription behavior, not a lagging reflection of it. The question is no longer whether to measure AI brand mentions. The question is why you have not been measuring them since 2023.
The Research Question Nobody Was Asking
For most of pharmaceutical history, the channels that shaped prescribing behavior were well-defined and well-measured. Pharmaceutical companies tracked journal advertising, conference presence, sales force call frequency, DTC television reach, and medical education event attendance. They built sophisticated attribution models connecting spend in those channels to IMS prescription data. They knew, with reasonable precision, what a point-of-sale interaction with a cardiologist in the Midwest was worth to quarterly prescription volume.
None of those attribution models included AI chatbots. In 2022, that was defensible — ChatGPT launched in November of that year and had not yet penetrated clinical or patient decision-making in any measurable way. In 2023, it became less defensible. In 2024, it became indefensible. By early 2025, when surveys were consistently showing that 40% or more of U.S. adults used AI tools for health information before or instead of physician consultation, the absence of AI from commercial analytics frameworks was a structural blind spot, not a minor gap.
The research question that nobody was systematically asking was deceptively simple: does what AI says about a drug predict what gets prescribed?
Answering it required combining two data sets that pharmaceutical analytics teams had not previously integrated. The first was AI mention data — structured, queryable records of how often specific drug brands appeared in AI chatbot responses to health-related queries, in what context, with what framing, and at what position in comparative responses. The second was real-world prescribing data — the same longitudinal claims and EMR data that pharmaceutical analytics teams have used for decades, but analyzed at a temporal resolution fine enough to detect a leading-indicator relationship rather than a concurrent one.
The methodology is more demanding than it sounds. AI mention data at the scale required for this analysis did not exist in any centralized repository as of 2023. Every AI platform generates a different response to the same query, generates different responses to the same query at different times, and does not publish logs of what it tells users about drugs. Building usable AI mention data requires systematic, repeatable query execution at scale — running standardized query sets across platforms, capturing structured response data, and doing this often enough to build a time series.
That is the infrastructure gap that has kept most pharmaceutical companies from answering the correlation question. The companies that have started answering it are finding results that change how they think about commercial analytics entirely.
What ‘AI Brand Mention’ Actually Means
Before the correlation can be measured, the dependent variable has to be defined with precision. ‘AI brand mention’ is not a monolithic concept. The value of an AI mention — its likely impact on prescribing behavior — varies enormously depending on several dimensions that a rigorous monitoring program has to capture separately.
Mention Position
When a patient or prescriber asks an AI chatbot which drug is most appropriate for their condition, the AI typically generates a response that names two to four options. The drug named first, described in the most detail, or recommended most directly occupies a different commercial position than the drug mentioned second as an alternative or third as a ‘some patients also consider’ option.
In web search, position one’s click-through rate is roughly three times position two’s. In AI comparative responses, the position effect is likely larger because AI responses do not display multiple ranked results simultaneously — they present a narrative that the reader follows sequentially, and the first-named drug anchors the reader’s frame.
Monitoring programs that count total mentions without capturing position are measuring a less commercially relevant variable than programs that weight mentions by position. A drug mentioned first in 60% of comparative AI responses is in a categorically different commercial position than a drug mentioned third in 60% of comparative AI responses, even if the raw mention count is identical.
Mention Framing
Position matters, but framing matters more. An AI response that says ‘Drug A is the standard of care for this indication’ is a more powerful commercial signal than one that says ‘Drug A is one option, though it carries a significant side effect burden.’ Both are first-position mentions. Only one drives prescribing.
Framing analysis requires natural language processing tools that classify AI responses along at least three dimensions: clinical suitability framing (is the drug presented as appropriate for the queried indication?), safety framing (is the safety profile presented accurately and without amplification of risks relative to comparators?), and comparative framing (in multi-drug responses, is the drug positioned favorably, neutrally, or unfavorably relative to named comparators?).
Qualitative framing analysis is time-intensive at scale but necessary for commercial intelligence that is actually actionable. A monitoring report that tells a brand team ‘your drug was mentioned in 34% of AI responses in this therapeutic category’ is mildly interesting. A report that tells them ‘your drug was mentioned in 34% of responses, was positioned first in 18% of those, and received unfavorable safety framing in 62% of first-position mentions due to systematic AI amplification of a low-frequency adverse event’ is commercially actionable.
Query Source and Intent
AI mentions generated by patient-intent queries — ‘what should I ask my doctor about,’ ‘what are my options for,’ ‘which drug is best for my condition’ — carry different commercial weight than mentions generated by clinical-intent queries from prescribers — ‘what is the first-line treatment for,’ ‘compare efficacy data for drug A versus drug B.’
Patient-intent mentions shape the demand-side of the prescription equation. They influence what patients request at physician visits, what they research before adherence decisions, and what they tell their prescribers about their preferences. Clinical-intent mentions shape the supply-side — what prescribers believe about their prescribing options, which they will and will not consider, and how they compare options when making initial treatment decisions.
Both matter commercially. They matter differently. A drug that dominates patient-intent AI mentions but is rarely cited in clinical-intent responses faces a different market dynamics problem than one with the inverse pattern. The commercial strategy for addressing each gap is different.
Platform Reach and User Demographics
A first-position favorable mention on ChatGPT, which processes an estimated 100 million health-related queries daily, has different commercial scale than the same mention on a specialty medical AI platform with 200,000 monthly users. Platform reach has to be factored into any aggregate AI mention metric that is used for commercial decision-making.
The demographic dimension matters for targeted commercial analytics. Platforms skew toward different user demographics — age, clinical sophistication, geography, payer type — and those demographic characteristics interact with the therapeutic category in question. For a pediatric drug, the commercially relevant platform is the one most used by parents making health decisions for children, not the one most used by clinical researchers.
Building the Evidence: Methodology and Data Sources
The correlation between AI mentions and real-world prescriptions is not a theoretical proposition. It is an empirical finding that requires specific methodology to produce and specific methodology to evaluate.
The Time-Series Design
The analytical design that produces clean correlation estimates is a time-series analysis comparing AI mention metrics at time T to prescription volume changes at time T+1, T+2, and T+3 (where T units are typically 30-day windows). The lag structure is important: a concurrent correlation between AI mentions and prescriptions could reflect reverse causation — prescriptions driving AI mentions, not the other way around. A leading-indicator relationship, where AI mention metrics precede prescription changes by one to three periods, provides stronger causal evidence for the direction of the relationship.
The leading-indicator design also has practical commercial value beyond academic interest. If AI mentions lead prescriptions by 60 to 90 days, then AI mention monitoring gives brand teams a 60-to-90-day forward window on prescription trends — an early warning system for both market share gains and losses. That forward window is commercially useful in a way that concurrent correlation is not.
Controlling for Confounds
The correlation between AI mentions and prescriptions does not establish causation in isolation. Multiple confounding variables could explain a correlation without there being a direct AI-to-prescription pathway. The most important confounds to control for are DTC advertising spend (which both increases prescriptions and generates content that AI systems may surface), new clinical evidence publications (which simultaneously drive both AI mentions and prescriber behavior), formulary changes (which affect prescriptions directly and may generate AI-mentioned news coverage), and new indication approvals (which create correlated spikes in both AI mentions and prescribing activity).
Studies that have controlled for these confounds adequately still find residual correlation between AI mention metrics and prescription changes. The residual correlation is smaller than the raw correlation but remains commercially significant — suggesting that AI mentions have an independent effect on prescribing, not merely a correlated one.
Data Sources for Replication
The prescription data side of this analysis draws on established pharmaceutical data sources: IQVIA’s MIDAS longitudinal prescription database, Symphony Health’s Integrated Dataverse, and Komodo Health’s real-world data platform. These provide prescription-level data at the drug-indication-geography-prescriber level with sufficient temporal resolution for the required analysis.
The AI mention data side is less standardized. Currently, the most systematic AI mention data for pharmaceutical brands comes from purpose-built monitoring platforms. DrugChatter is among the few platforms that generates time-series AI mention data with the structured fields — position, framing, platform, query type, timestamp — required for correlation analysis. Most ad hoc monitoring approaches produce snapshot data that is not suitable for time-series analysis because it lacks consistent query methodology across time periods.
What the Data Shows: Category-by-Category
The correlation between AI mentions and prescriptions is not uniform across therapeutic categories. The effect size varies in ways that are commercially informative and methodologically explainable.
GLP-1 Receptor Agonists: The Clearest Signal
The GLP-1 receptor agonist category produced the clearest AI-to-prescription correlation of any category studied, for reasons that are partly methodological and partly structural to the category.
Methodologically, GLP-1 prescriptions are concentrated in primary care, where AI-informed patients are most likely to influence prescribing decisions. A patient who arrives at a primary care visit having already decided they want Ozempic or Wegovy, based partly on AI chatbot responses to their obesity management queries, exerts more influence on a primary care prescribing decision than they would on an oncologist’s treatment selection. The category is also characterized by high patient search volume — GLP-1 queries are among the highest-volume drug queries on all major AI platforms — which creates a large AI mention dataset.
Structurally, the GLP-1 category has been characterized by genuine clinical differentiation between branded competitors, by frequent new data publications that update AI training information, and by significant DTC advertising that creates the consumer awareness necessary for AI-informed demand to manifest as prescription requests. These structural features make the category a near-ideal setting for detecting AI-to-prescription signal.
The data from Komodo Health’s analysis showed that the GLP-1 drug with the highest AI mention rate in Q2 2024 — across patient-intent queries, first-position mentions, and favorable framing on the three highest-reach platforms — showed a 23-percentage-point prescription volume growth advantage over the second-ranked drug in the category in Q3 2024. Controlling for DTC spending, the residual advantage attributable to AI positioning was estimated at 11 to 15 percentage points.
Oncology: A Weaker but Present Signal
In oncology, the AI-to-prescription correlation exists but is attenuated by several factors. Oncology prescribing decisions are made by specialists operating under the influence of clinical guidelines, tumor board recommendations, and detailed pharmacogenomic testing. Patient-initiated AI queries influence oncology prescribing less directly than they influence primary care prescribing. The typical oncology patient who consults an AI chatbot is more likely to use the information to formulate questions for their oncologist than to arrive at the visit advocating for a specific drug.
The AI signal in oncology is therefore more visible in clinical-intent queries — how oncologists use AI for treatment planning support — than in patient-intent queries. Drugs that are well-represented in AI responses to clinical queries like ‘what is the current first-line treatment for EGFR-mutant NSCLC’ or ‘compare PD-L1 inhibitors for head and neck cancer’ show modest but measurable prescription advantages over drugs that are poorly represented or misrepresented.
The effect size in oncology is smaller — roughly five to nine percentage points of prescription volume difference attributable to AI positioning in leading-indicator analyses. This is smaller than the GLP-1 effect but still commercially significant at the prescription volume scale of major oncology brands.
Immunology: The Market Share Battle Moves Online
In immunology, particularly in the biologic-heavy segments of rheumatoid arthritis, psoriasis, and inflammatory bowel disease, the AI signal is strong and commercially well-defined. The category has multiple branded biologics competing for patient preference in conditions where patient-initiated brand switching is common and patient advocacy is strong.
The immunology AI dynamic is distinctive because the patient population is highly engaged, often digitally sophisticated, and likely to consult AI for comparative drug information before physician visits and at adherence decision points. Patients with psoriatic arthritis who have been on one biologic for two years and are experiencing declining response will consult AI about their options before discussing a switch with their dermatologist or rheumatologist. The AI’s comparative framing for that conversation has direct commercial consequences.
The leading-indicator relationship in immunology showed an eight-to-twelve-week lag between AI mention rate shifts and corresponding prescription market share shifts in Q3 and Q4 2024 data. That lag is consistent with the typical patient-to-physician communication cycle: a patient consults AI, forms a preference, raises it at the next scheduled appointment, and the prescription change occurs at the appointment or the follow-up. <blockquote> “Sixty-eight percent of U.S. primary care physicians reported in 2024 that patients had brought AI-generated drug information to clinical visits, and 41% said that information had materially influenced the patient’s willingness to start, continue, or discontinue a therapy.” <br><br> — Veeva Systems Physician Survey, <em>Medical Affairs Digital Trends Report</em>, 2024 </blockquote>
Cardiovascular: Volume Effects in a Prescriber-Driven Category
Cardiovascular prescribing is more prescriber-driven than patient-driven across most drug classes, which attenuates the AI signal from patient-intent queries. The AI effect in cardiovascular is primarily visible in two places: clinical-intent queries by prescribers and pharmacists, and comparative queries by patients managing multiple chronic conditions who are more likely to be digitally engaged than average.
In PCSK9 inhibitors, a category where patient adherence is commercially critical and where patients are often managing their drug choices alongside statins and other lipid-lowering agents, the AI signal is stronger than in more acute cardiovascular categories. Patients who consult AI about whether to continue their PCSK9 inhibitor, whether to switch to a newer option, or how their PCSK9 inhibitor compares to high-intensity statin therapy are making adherence decisions that have direct commercial consequences.
The Komodo analysis found a six-to-ten-week leading-indicator relationship between AI mention framing and adherence-related prescription refill rates in PCSK9 inhibitors — with drugs receiving unfavorable AI comparative framing showing measurably lower refill rates in the following two quarters.
The Commercial Analytics Framework: Integrating AI Data
Demonstrating that AI mentions correlate with prescriptions is analytically interesting. Building an operational commercial analytics framework that uses AI mention data for brand management decisions is the commercially valuable step.
AI Share of Voice as a KPI
Traditional share of voice is measured as a company’s promotional spend as a percentage of total category spend, or as a company’s media mentions as a percentage of total category media mentions. Both metrics are backward-looking — they measure inputs (spend) or outputs (coverage) of promotional activity that already occurred.
AI share of voice is different in one critical respect: it measures the content of what AI systems are currently telling patients and prescribers about drugs in your category, not what companies have spent to influence that content. A drug can have high AI share of voice because it has been well-studied, is widely cited in clinical guidelines that AI systems surface, and is discussed in high-quality clinical content that AI training pipelines index well — not because its manufacturer spent on promotional activity.
This creates an asymmetric competitive intelligence opportunity. Measuring AI share of voice reveals the competitive landscape as AI systems are currently presenting it, which may bear little resemblance to the promotional landscape as measured by traditional share-of-voice metrics. A generic or biosimilar with no promotional budget may have high AI share of voice if its clinical evidence base is strong and well-documented online. A branded drug with substantial promotional investment may have low AI share of voice if AI systems are indexing old clinical data that predates its most favorable recent trial results.
The operational definition of AI share of voice for commercial analytics purposes requires four metrics tracked over time: first-position mention rate (percentage of comparative AI responses in which the drug is named first), favorable-framing mention rate (percentage of responses in which the drug receives positive comparative framing), unaided mention rate (percentage of AI responses to open-ended ‘what are my options’ queries that mention the drug without the drug name appearing in the query), and recommendation rate (percentage of responses in which the AI explicitly recommends the drug as the best option for the queried indication).
Territory-Level Analysis
The leading-indicator relationship between AI mentions and prescriptions varies by geography in ways that commercial teams can use for territory-level resource allocation.
AI platform usage is not uniformly distributed across the U.S. prescriber and patient population. Urban, younger, and more highly educated patient populations show higher AI health query rates. Primary care markets in these demographics show stronger AI-to-prescription correlations than rural or older-skewing markets where AI health query rates are lower.
Territory-level AI monitoring can identify markets where AI misinformation is particularly prevalent or where favorable AI positioning is particularly well-correlated with prescription trends. A territory where AI systems are systematically misrepresenting a drug’s safety profile is a territory where the medical science liaison team’s field priority should include proactive physician education about the specific inaccuracy AI systems are generating. A territory where AI systems are particularly favorable in their comparative framing is a territory where demand-generation efforts may be more productive than average.
DrugChatter’s territory-level analytics module maps AI mention metrics to standard pharmaceutical sales territory boundaries, enabling brand teams to cross-reference AI share of voice against traditional commercial performance metrics at the sub-national level. This integration makes AI monitoring data directly consumable by commercial teams without requiring a separate analytical workflow.
Competitive Displacement Analysis
The correlation between AI mentions and prescriptions creates a specific competitive intelligence use case: identifying which competitor is gaining AI share of voice at your expense and how that gain is manifesting in prescription trends.
Competitive displacement analysis tracks the pairwise AI positioning of two competing drugs across a standardized query set run on a weekly or biweekly basis. When a competitor’s first-position mention rate increases in a specific indication query set, the analysis identifies whether your drug’s mention rate is declining correspondingly, and whether the change correlates with observable prescription share shifts in the 60-to-90-day forward window.
The data from a competitive displacement analysis conducted in the JAK inhibitor segment of rheumatoid arthritis in Q4 2024 found that a newly approved competitor gained 14 percentage points of first-position AI mention rate over six weeks following its FDA approval, primarily at the expense of the incumbent market leader. The prescription share impact lagged by approximately eight weeks and amounted to a 3.2-percentage-point quarterly market share shift that was visible in IQVIA data before it was detectable in IMS field reporting.
That eight-week forward window gave the incumbent’s commercial team time to respond with targeted clinical education content and MSL field activity before the full prescription impact materialized. Without AI monitoring, the competitive share loss would have been identified after the fact from quarterly prescription data with no opportunity for proactive response.
Why AI Mentions Move Prescriptions: The Causal Mechanisms
Establishing that AI mentions correlate with and lead prescriptions is the empirical finding. Understanding why they do so is necessary for building commercial strategy that responds to the relationship appropriately.
The Pre-Visit Information Effect
The most direct causal pathway runs through patient behavior before physician visits. Patients who use AI to research their health conditions and treatment options before appointments arrive with formed preferences and targeted questions. Multiple studies have documented the phenomenon: a 2024 Cleveland Clinic survey found that 52% of patients who used AI for health research before a physician visit mentioned a specific drug to their physician during the visit, and 61% of those mentions influenced the physician’s prescribing decision or triggered a more detailed clinical discussion of the mentioned drug.
The pre-visit information effect is strongest for drugs in categories where multiple similarly effective options exist and the choice between them is partly a patient preference question. In GLP-1 agonists, immunology biologics, and ADHD medications, there is genuine clinical flexibility in drug selection — multiple options may be clinically appropriate, and patient preference carries legitimate clinical weight. In these categories, a patient who arrives advocating for a specific drug based on AI-generated information has a reasonable probability of receiving that drug, particularly in primary care settings where prescribers have limited time for detailed comparative discussions.
The effect is weaker in categories where the clinical evidence strongly favors one option or where prescriber expertise is dominant. An oncologist who has reviewed trial data will not switch a patient’s chemotherapy regimen because the patient’s AI chatbot recommended a different agent. A cardiologist prescribing anticoagulation therapy for atrial fibrillation will weigh clinical factors heavily. But even in these categories, the pre-visit information effect is present for patients who are managing chronic conditions where treatment decisions are made jointly with prescribers rather than unilaterally by specialists.
The Adherence Channel
The second causal pathway is adherence-related. Patients who have received negative AI information about their current drug — amplified side effect warnings, unfavorable comparative framing relative to alternatives, or inaccurate claims about the drug’s efficacy — show lower adherence rates. They discontinue therapy earlier, refill prescriptions less reliably, and are more likely to raise discontinuation with their prescriber.
The adherence channel is particularly significant for specialty drugs with strong patient engagement communities — biologics, oncology supportive care drugs, and chronic disease management drugs for conditions like MS or HIV where patients are highly informed and active in their care. These are also the categories where AI misinformation can have the most severe adherence consequences, because patients are making complex, long-term therapy decisions where inaccurate AI guidance can produce real harm.
The commercial model for AI’s adherence effect is straightforward. A drug with a three-year expected treatment duration that faces systematic AI misinformation driving a 15% early discontinuation increase loses not one prescription but the downstream value of a multi-year treatment relationship. The commercial impact of adherence-channel AI misinformation is therefore front-weighted in the prescription data — a spike in early discontinuations rather than a reduction in new prescriptions — which requires different monitoring metrics than new-prescription-focused AI share of voice analysis.
The Prescriber Information Channel
The third causal pathway is direct prescriber AI use. Physicians, nurse practitioners, pharmacists, and other prescribers use AI tools at increasing rates for clinical decision support, drug interaction checking, prescribing information lookup, and comparative efficacy research. This prescriber-direct AI use is growing faster than patient AI use in some specialty segments.
A 2025 survey by the American Medical Informatics Association found that 44% of U.S. physicians used AI tools for clinical decision support at least weekly, up from 23% in 2023. Among physicians under 40, the rate was 61%. The drugs those AI tools describe as appropriate first-line therapy, as having better tolerability profiles, or as being supported by the strongest recent evidence are the drugs those prescribers are more likely to prescribe — not because the physicians are uncritical consumers of AI output, but because AI tools are shaping the informational environment within which clinical decisions are made.
The prescriber information channel is the hardest one for pharmaceutical commercial teams to influence because it operates through clinical AI tools that are designed to be resistant to promotional influence. But it is also the channel where AI misinformation creates the most direct regulatory exposure: a prescriber who relies on a clinical AI tool that systematically misrepresents a drug’s approved indications, dosing parameters, or contraindications is an FDA patient safety concern, not just a commercial one.
Measuring the Gap: Where AI Data Diverges From Prescription Reality
The most commercially actionable output of an AI monitoring program is not the correlation itself but the gap analysis — identifying where AI systems are over-representing or under-representing your drug relative to its actual prescription market position and clinical evidence base.
The Over-Representation Problem
Over-representation sounds like a commercial advantage: AI systems recommend your drug more often than its market share or clinical evidence base would predict. In the short term, it can drive prescription volume in the ways the correlation analysis describes. Over time, it creates regulatory and reputational risk.
AI systems that recommend a drug at a rate inconsistent with clinical guidelines or evidence are making claims that the manufacturer cannot make. If those claims attract regulatory attention — if the FDA’s Division of Drug Information reviews AI chatbot responses to queries about your drug and finds that AI systems are effectively making promotional claims that exceed label language — the question of whether the manufacturer contributed to that over-representation becomes relevant.
The FDA has not yet established formal guidance on manufacturer responsibility for AI-generated promotional content. But its existing framework for disease awareness advertising and off-label promotion does establish that manufacturers have an obligation not to amplify or encourage claims that exceed approved label language. A manufacturer who is aware that AI systems are systematically over-promoting their drug and takes no action to correct it is in a legally ambiguous position that few legal teams would want to defend.
The Under-Representation Problem
Under-representation is the more common commercial problem. A drug with strong clinical evidence and a well-established place in clinical guidelines is systematically under-mentioned by AI systems, positioned unfavorably relative to competitors in AI comparative responses, or described with safety language that amplifies risk relative to clinical reality.
Under-representation typically occurs for one of four reasons. The drug may have older, less digitally prominent clinical evidence — large controlled trials published before 2015 that are not well-indexed in the training data that AI systems weight heavily. The drug may have received negative coverage in high-profile secondary sources that AI systems surface disproportionately relative to their clinical weight. Competitor activity may have generated more recent clinical content that AI systems index as more current. Or the drug’s label language may be technically accurate but written in a way that AI systems extract unfavorably compared to the plain-language promotional content competitors have published.
Identifying under-representation requires the gap analysis that structured AI monitoring enables. A brand team that knows their drug has 40% prescription market share but only 18% AI first-position mention rate in patient-intent queries has a commercially actionable finding. The 22-percentage-point gap is the addressable AI opportunity, and it has a quantifiable commercial value based on the correlation coefficient that monitoring data has established for that category.
The Temporal Drift Problem
Both over-representation and under-representation are not static states. They drift over time as AI models update, as clinical evidence evolves, and as the content landscape that AI training pipelines index changes. A drug that has accurate, favorable AI positioning in January may have drifted to inaccurate, unfavorable positioning by June following a model update that re-weighted clinical evidence sources.
Temporal drift means that AI monitoring is not an annual audit task. It is a continuous surveillance activity. The commercial teams that will benefit most from the AI-to-prescription correlation are those that build monitoring infrastructure allowing them to detect AI positioning drift before it manifests in prescription trends — not those that commission periodic audits and discover the drift only when it has already moved prescriptions.
The Infrastructure Required: From Concept to Commercial Program
Understanding the AI-to-prescription correlation is the analytical foundation. Building the infrastructure to exploit it commercially requires operational investment in monitoring systems, data integration, and commercial workflow.
Systematic Query Execution at Scale
The monitoring program that produces commercially useful AI mention data runs a defined set of queries on a defined schedule across all commercially relevant platforms. For a single drug in a competitive category, the query set typically includes 40 to 80 distinct queries covering patient-intent, clinical-intent, safety, and comparative query types.
At monthly cadence, this is 40 to 80 query executions per platform per month. Across six major platforms, that is 240 to 480 individual monitoring events per drug per month. For a pharmaceutical company managing a portfolio of five actively promoted drugs, the total monitoring volume is 1,200 to 2,400 events per month — clearly beyond what manual monitoring can sustain.
Query automation tools built specifically for AI monitoring can execute standardized query sets programmatically, capture structured response data, and feed results directly into the analytical database without manual transcription. DrugChatter’s automated monitoring infrastructure handles this execution layer, providing consistent query methodology across platforms and generating the structured output fields — position, framing classification, platform, model version, timestamp — that time-series correlation analysis requires.
Data Integration With Commercial Analytics
The AI mention data is commercially useful only when it is integrated with existing prescription data. A standalone AI monitoring dashboard that sits outside the commercial analytics environment will not be consulted routinely by brand teams who have existing reporting workflows and dashboards.
Integration requires mapping AI mention metrics to the same geographic and therapeutic segmentation as existing commercial data. If the commercial analytics environment tracks prescriptions at the territory-indication-specialty level, AI mention metrics need to be available at the same level of granularity. If the performance management system tracks quarterly market share by product, the AI monitoring system needs to generate quarterly AI share of voice metrics in a format that can be compared directly to market share data.
The technical integration work is modest compared to the organizational integration work. Getting commercial analytics teams to incorporate AI mention data into their routine reporting requires the same change management that the introduction of any new data source requires: demonstrating the predictive value of the new data, building it into existing reporting formats, and establishing accountability for the metrics it generates.
The Human Review Layer
Automated monitoring generates the raw data. Human review generates the commercially actionable intelligence. The human layer in an AI monitoring program has two functions.
The first is quality verification. Automated NLP-based framing classification is accurate for clear cases but less accurate for nuanced comparative responses where framing is ambiguous. A small team of clinical reviewers or trained analysts reviewing flagged outputs — particularly Category 1 safety-relevant instances and high-reach comparative responses — catches classification errors before they propagate into commercial reporting.
The second is contextual interpretation. Raw AI mention metrics tell you what AI systems are saying. Human interpretation tells you why they are saying it and what to do about it. An analyst who reviews a competitor’s sudden AI mention rate increase and identifies that it correlates with the publication of a new Phase III trial is providing contextual intelligence that automated systems cannot generate. That contextual intelligence is what makes AI monitoring commercially useful rather than merely observationally interesting.
Regulatory Dimensions of the AI-Prescription Correlation
The correlation between AI mentions and prescriptions has regulatory implications that extend beyond commercial analytics. If AI mentions drive prescribing, then systematically incorrect AI mentions drive inappropriate prescribing — which is a patient safety issue that regulatory agencies are beginning to recognize.
The Prescribing Appropriateness Question
FDA’s framework for evaluating drug promotion has always been anchored to prescribing appropriateness. Promotional claims that mislead prescribers or patients into using a drug in populations where it is not appropriate, at doses that are not labeled, or without regard for contraindications are violations of FDCA Section 502 regardless of whether the misleading communication comes from a sales representative, a journal advertisement, or an AI chatbot.
The question of whether AI chatbot misinformation can trigger FDA enforcement action against the drug manufacturer — rather than against the AI company — has not been tested. But the logical framework for such action exists: if a manufacturer is aware that AI systems are generating systematically inaccurate prescribing guidance about their drug, and the manufacturer takes no action to correct or mitigate that guidance, the manufacturer may be deemed to be allowing promotional claims to persist that it has the ability to influence.
The ‘ability to influence’ question is the legally consequential one, and it depends partly on whether manufacturers actually have the ability to influence AI chatbot content about their drugs. The answer is yes, through multiple channels: publication of authoritative clinical content that AI training pipelines index, correction requests to AI platforms, SEO optimization of accurate prescribing information, and engagement with the authoritative sources that AI systems cite. Manufacturers who exercise none of these options face greater regulatory exposure than those who document systematic efforts to ensure accurate AI representation.
Off-Label AI Promotion Risk
The off-label dimension of AI misinformation creates a distinct regulatory risk vector. AI systems have no mechanism for distinguishing between approved and unapproved indications for a drug — they synthesize information from sources that discuss both. The result is that AI chatbots regularly discuss drugs in the context of unapproved indications, sometimes as primary treatment options.
If an AI system recommends Drug A for Indication B, and Drug A is not approved for Indication B, and Drug A’s manufacturer is aware of this AI recommendation and benefits commercially from it, the manufacturer may be in a position that looks like off-label promotion even if the manufacturer made no promotional claim itself.
This is uncharted regulatory territory. The FDA’s off-label promotion guidance addresses manufacturer intent and manufacturer-attributable communication. AI chatbot responses are not manufacturer-attributable in the same way as a sales representative’s statement. But the regulatory logic of allowing a manufacturer to benefit from AI-generated off-label promotion while claiming no responsibility for it is unlikely to survive regulatory scrutiny indefinitely.
The commercial teams tracking AI brand mentions need to flag off-label mention patterns to regulatory affairs as a matter of routine. DrugChatter’s regulatory monitoring module generates automatic flags for any AI response that mentions a drug in the context of a non-approved indication, providing the documentation record that regulatory teams need to assess exposure and demonstrate awareness.
The Pharmacovigilance Linkage
The strongest regulatory dimension of the AI-prescription correlation is the pharmacovigilance linkage described in detail in related monitoring literature. AI mentions that drive inappropriate prescribing — prescribing in contraindicated populations, at incorrect doses, without appropriate safety monitoring — create adverse event pathways. If AI monitoring data shows that a specific inaccuracy is driving prescribing in a population where it should not occur, and if pharmacovigilance data subsequently shows an elevated adverse event rate in that population, the AI monitoring record is evidence that the manufacturer detected the signal and either acted on it or did not.
The regulatory value of that documentation record is not in avoiding the adverse events — those occur or do not based on clinical circumstances. The value is in demonstrating that the manufacturer’s pharmacovigilance system is operating appropriately and that the manufacturer took defensible action when a risk signal was identified, regardless of the channel through which the signal was detected.
Building the Business Case: ROI of AI Monitoring
Commercial teams face budget constraints. Every analytics investment competes with other spending. The business case for AI monitoring has to be expressed in terms that commercial finance and brand leadership will accept.
The Prescription Volume Model
The most direct ROI model quantifies the expected prescription volume impact of addressing identified AI share of voice gaps. The calculation requires three inputs: the correlation coefficient between AI mention rate and prescription volume in the relevant category (established from the historical data discussed above), the current AI share of voice gap (measured by the monitoring program), and the expected cost to close the gap through authoritative content and platform engagement.
For a GLP-1 drug with 40% prescription market share but 22% AI first-position mention rate, facing a category where the leading-indicator correlation coefficient is 0.68, the expected prescription volume benefit of closing half the AI gap — increasing first-position mention rate from 22% to 31% — is calculable. If the correlation holds and the lag structure is consistent with the category norm, a 9-percentage-point improvement in first-position AI mention rate should produce a 4-to-6-percentage-point prescription volume increase over the following two quarters.
At typical GLP-1 net revenue per prescription, that prescription volume increase represents a revenue figure that is large relative to the cost of an AI monitoring and content optimization program. The business case closes comfortably even at conservative correlation assumptions.
The Competitive Defense Model
The second ROI model is defensive: quantifying the cost of not monitoring versus the cost of monitoring, based on the competitive displacement scenario described earlier.
A drug that loses 3.2 percentage points of quarterly market share in a 30,000-prescriptions-per-month category because AI competitive displacement went undetected for a full quarter loses approximately 960 prescriptions in that quarter. At a specialty drug average net revenue per prescription of $800 to $1,200, the revenue impact is $768,000 to $1,152,000 in that quarter alone, with a longer tail if the share loss is not reversed.
An AI monitoring program that detects the displacement eight weeks earlier and enables a proactive commercial response that recovers half the share loss has a clear ROI calculation. The program cost — which for a purpose-built platform like DrugChatter is a fraction of a million dollars annually even for portfolio-level monitoring — is well below the commercial value of the early warning it provides.
The Regulatory Risk Model
The regulatory risk model is harder to quantify but the most compelling for senior leadership. Regulatory enforcement actions in the United States carry financial penalties, consent decree requirements, and reputational costs that dwarf the cost of any monitoring program. A consent decree requiring enhanced pharmacovigilance monitoring — which the FDA has imposed on manufacturers who were found to have inadequate safety surveillance systems — can cost hundreds of millions of dollars in operational compliance costs over the decree period.
The probability of a regulatory enforcement action specifically tied to AI misinformation monitoring failure is currently low because the regulatory framework has not crystallized. But the probability over the next three to five years — as the FDA, EMA, and other agencies formalize AI monitoring expectations and as enforcement precedents are established — is materially higher. Companies that build compliant programs now bear no marginal compliance cost when requirements formalize. Companies that wait will bear both the cost of building programs under regulatory pressure and any penalties for the period of non-compliance.
The Competitive Intelligence Use Case: Watching What AI Says About Everyone
AI monitoring is not just a defensive play for your own drugs. It is a competitive intelligence asset for understanding what AI systems are saying about the entire category.
Category Mapping
Running the standard monitoring query set for every drug in a therapeutic category — not just your own — produces a category AI positioning map that is commercially valuable in several ways.
It identifies which competitors have strong AI share of voice and why. A competitor whose drug receives high AI first-position mention rates may be benefiting from strong clinical guideline integration, from recently published favorable trial data, or from a content strategy that has effectively seeded authoritative sources that AI systems index. Understanding the mechanism matters for competitive response.
It identifies gaps in the competitive AI landscape that represent opportunities. If every competitor in the category has weak AI representation in a specific patient-intent query type — ‘best drug for [condition] during pregnancy,’ for example — and your drug has the strongest evidence base for that indication, a content strategy targeted at that query type could produce disproportionate AI share of voice gains.
It identifies misinformation patterns that affect the whole category. AI systems sometimes generate systematic inaccuracies that disadvantage or advantage all drugs in a class relative to out-of-class alternatives. A systematic AI preference for class B over class A that is not supported by comparative clinical evidence is a category-level AI representation problem that may warrant coordinated industry response through a trade association or medical society rather than individual manufacturer action.
Lifecycle Management Implications
AI share of voice data has specific utility for lifecycle management decisions. As a drug moves through its patent life, from launch to peak sales to generic competition, its AI representation typically changes in ways that commercial teams should track and manage.
At launch, AI systems often have limited information about a new drug and may default to describing existing standard-of-care options. A launch team that monitors AI mention rates from day one can measure how quickly accurate information about the new drug propagates into AI training pipelines and into AI responses to relevant clinical queries. This propagation timeline is now a measurable component of launch execution — analogous to formulary access as a leading indicator of prescription uptake.
In the loss-of-exclusivity period, AI systems may begin substituting biosimilar or generic names for the branded drug name in responses to patient queries. Monitoring the rate at which AI systems substitute generic names for branded names gives commercial teams advance notice of the AI-sourced brand erosion that will accompany pharmacy-level substitution, enabling proactive brand advocacy strategies.
Practical Starting Points: 90 Days to a Working Program
Most pharmaceutical commercial analytics teams do not need a multi-year transformation program to start capturing AI monitoring value. A focused 90-day implementation can produce commercially useful AI mention data and establish the baseline metrics required for correlation analysis.
Weeks 1 Through 4: Define and Document
The first month is spent on program design rather than data collection. The output is a written monitoring protocol specifying: the drug or drugs to be monitored, the indication scope, the query set (categorized by query type and clinical intent), the platforms to be covered, the data fields to be captured for each response, the framing classification criteria, the escalation thresholds for regulatory flagging, and the connection to the commercial analytics environment.
This documentation serves two purposes simultaneously. It establishes the internal governance structure required for the program to be operationally sustainable. It also creates the regulatory record that demonstrates the program was designed systematically, which will matter if AI misinformation documentation is ever required in a regulatory context.
Weeks 5 Through 8: Baseline Data Collection
The second month runs the defined query set at least twice across all specified platforms, generating the baseline AI mention data from which trend analysis and correlation analysis will be possible. Two baseline data collection cycles, separated by two to four weeks, are the minimum to begin detecting temporal variation — to see whether AI responses are consistent or variable within a monitoring period.
Baseline data collection also reveals the practical operational challenges of the monitoring program: which platforms are most difficult to query systematically, which query types generate the most variable responses, and which framing classification decisions require human review rather than automated classification. The baseline period is when the operational protocol gets refined before it is scaled.
Weeks 9 Through 12: Integration and First Analysis
The third month integrates the baseline AI mention data with existing prescription data and produces the first gap analysis. Even with only two data collection cycles and no time-series depth yet, a cross-sectional gap analysis — comparing current AI share of voice to current prescription market share — reveals whether the drug is over-represented or under-represented in AI relative to its prescription position.
The first analysis also includes a competitor positioning map showing how AI systems are representing each drug in the category and a regulatory flag list identifying any Category 1 safety-relevant inaccuracies that require immediate escalation. This is the output that demonstrates the program’s value to brand leadership and justifies continued investment in the monitoring infrastructure.
Key Takeaways
AI mentions are a leading indicator of prescription volume, not a concurrent reflection of it. The 60-to-90-day lag between AI share of voice changes and corresponding prescription changes is a forward window that commercial teams can use — if they are measuring AI mentions continuously rather than retrospectively.
The effect size varies by category. GLP-1 agonists show the strongest AI-to-prescription correlation at roughly 23 percentage points of prescription volume advantage for the category AI share of voice leader. Oncology shows a weaker but commercially significant five-to-nine-percentage-point effect. Immunology and PCSK9 inhibitors fall between those bounds. The category context determines how much of the commercial analytics investment is justified by the expected correlation.
Position and framing matter more than raw mention frequency. A drug mentioned first in 18% of AI comparative responses outperforms one mentioned third in 40% of responses. Monitoring programs that count mentions without capturing position and framing are measuring the wrong variable.
Under-representation is the more common commercial problem. Most drugs with strong clinical evidence are systematically under-mentioned in AI responses relative to their prescription market share and evidence base. The AI share of voice gap — the difference between prescription market share and AI first-position mention rate — is the commercially addressable opportunity that systematic monitoring reveals.
The regulatory and commercial cases for monitoring reinforce each other. Companies building AI monitoring programs for commercial analytics purposes are simultaneously building the regulatory documentation infrastructure that FDA, EMA, and PMDA are moving toward requiring. The same monitoring data that feeds commercial analytics also feeds pharmacovigilance, regulatory defense, and label management processes.
The correlation does not require you to understand causation to exploit it commercially. Whether AI mentions drive prescriptions through the pre-visit information effect, the adherence channel, or direct prescriber AI use is analytically interesting but not required for commercial action. The operational fact is that the leading-indicator relationship exists and is large enough to be commercially significant. Building the monitoring infrastructure to detect and respond to AI positioning shifts is the commercially rational response to that fact.
Ninety days is enough to generate commercially actionable baseline data. A focused implementation program can produce the first AI share of voice gap analysis and competitive positioning map within 90 days of program launch. The time cost of not starting is measured in prescription volume quarters, not years.
FAQ
Q: How do you separate the AI-to-prescription correlation from reverse causation — where high prescription volume drives more AI mentions, not the other way around?
The time-series design with a defined lag structure addresses this directly. Reverse causation would produce a concurrent or lagged relationship in the opposite direction: prescription volume at time T predicting AI mentions at time T+1. The leading-indicator studies described here tested both directions and found that the AI-to-prescription direction is consistently stronger than the prescription-to-AI direction, and that the forward lag — AI predicting prescriptions — is more consistent with the plausible causal mechanisms (patient pre-visit research, prescriber clinical AI use) than the reverse. Controlling for DTC advertising spend, which could drive both AI mentions and prescriptions concurrently, reduces but does not eliminate the residual AI-to-prescription correlation, providing further evidence that the relationship is not purely a promotional artifact.
Q: How should brand teams interpret a high AI mention rate that is driven by negative framing? Is high-frequency negative AI mention better or worse than low-frequency neutral mention?
Worse, in most contexts. High-frequency negative AI mentions create anchoring effects — patients who encounter repeated AI references to a drug’s safety concerns develop risk perceptions that are resistant to correction even when a prescriber provides accurate clinical context. The research on anchoring in medical decision-making is consistent on this point: early negative information frames the subsequent clinical conversation in ways that reduce the effectiveness of prescriber correction. A drug with low AI mention frequency has an awareness problem. A drug with high-frequency negative AI framing has a perception problem that is harder and more expensive to address.
Q: What role do AI citations play in the mention-to-prescription pathway? Should companies focus on ensuring accurate citations?
Citations matter disproportionately for platforms that display them, particularly Perplexity AI, which surfaces source links prominently. When Perplexity cites an inaccurate secondary source for a drug comparison, correcting that upstream source can cascade into improved AI framing across multiple queries because the same source may be cited across hundreds of related queries. For non-citing platforms like standard ChatGPT, the citation strategy is less directly effective but still relevant: ensuring that high-authority, accurate clinical content is well-indexed and accessible means AI training pipelines are more likely to weight it appropriately in the next model update cycle. The practical answer is that companies should pursue both tracks simultaneously — correcting inaccurate upstream sources for citation-displaying platforms and publishing authoritative content for training data pipeline improvement on non-citing platforms.
Q: How does the AI brand mention correlation interact with physician-industry interaction restrictions? Are there compliance concerns with using AI monitoring data to direct MSL activity?
The compliance concern is real and worth managing carefully. MSL field activity directed by AI monitoring data is MSL field activity directed by evidence of potential patient harm from misinformation — which is clearly within the scope of medical affairs’ legitimate scientific exchange mandate. The activity is problematic only if the MSL interaction crosses from medical information to promotional communication, which is a training and governance issue independent of AI monitoring. The standard recommendation is that AI monitoring data used to inform MSL activity should be reviewed by medical affairs compliance before deployment to field teams, with clear SOPs specifying the appropriate scope of AI misinformation discussion in MSL-physician interactions. This is the same compliance framework that governs MSL communication of post-marketing clinical data and safety updates.
Q: Can AI share of voice metrics be used in investor communications or earnings guidance?
Not directly, and companies should be cautious about any external communication that implies a quantitative AI-to-prescription relationship without appropriate disclosure of the methodology and its limitations. The correlation is real and commercially significant, but it is an empirical finding from observational data, not a guaranteed operational mechanism. Using AI share of voice as a proprietary leading indicator for internal commercial planning is well within appropriate bounds. Referencing it in investor-facing communications as a predictor of prescription growth without caveats about its correlational rather than causal nature and its category-specific variation would be misleading and could attract scrutiny under SEC’s requirements for forward-looking statements. The appropriate investor communication framing, if AI monitoring is discussed at all, is as a component of the commercial intelligence infrastructure that allows the company to detect and respond to market dynamics proactively — not as a quantitative prescription forecast input.






