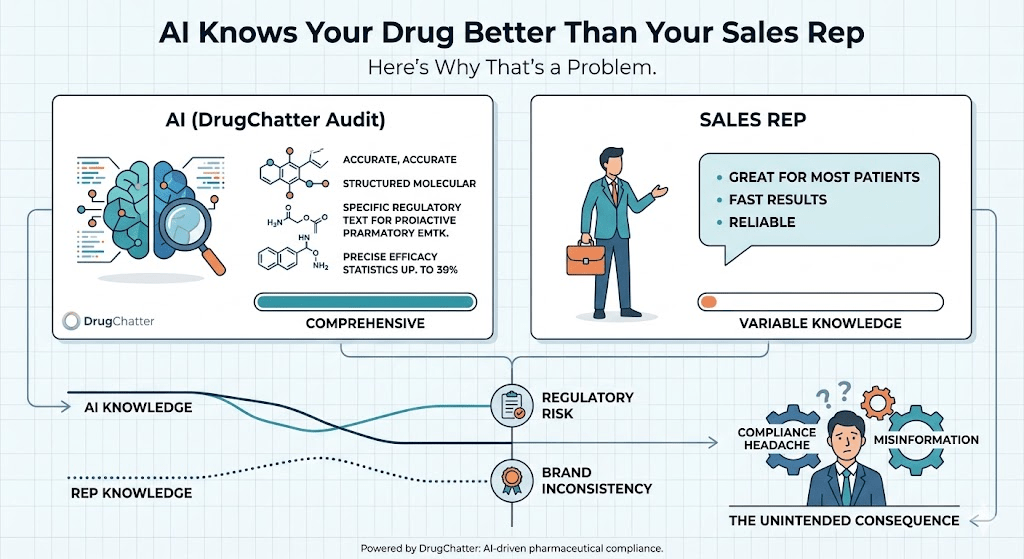
How artificial intelligence is tracking, shaping, and sometimes undermining pharmaceutical brand strategy — and what drug companies need to do right now
The first sign that something had shifted came not in a boardroom or an FDA docket, but in a Reddit thread. In early 2024, a rheumatoid arthritis patient posted a screenshot of a conversation with a popular AI assistant. She had asked it to compare two biologics for her condition. The AI had answered — confidently, completely, and with zero mention of the patient information hotline embedded in every pharma brand’s digital presence. It cited neither the drug company’s branded website nor the managed care pamphlet designed to steer patients toward preferred therapies.
It just answered. With clinical fluency. And she trusted it.
That moment — replicated millions of times daily across ChatGPT, Gemini, Claude, Perplexity, and a dozen emerging health-focused AI tools — is forcing pharmaceutical companies to rethink three decades of marketing architecture. The old model, built on controlled messaging through sales representatives, journal advertising, and patient advocacy relationships, assumes the company sits at the center of the information flow. AI destroys that assumption.
Drug companies are not ready. Most of them still measure brand health through monthly IMS prescribing data, quarterly unaided awareness surveys, and field force call logs. None of those instruments detect what an AI says about their drug at 11 p.m. when a patient is deciding whether to refill a prescription.
This is the problem DrugChatter was built to solve.
Why AI Models Have Become Pharma’s Most Powerful Unmanaged Stakeholder
In standard brand management, a pharmaceutical company can influence the information environment through a finite set of channels: the FDA-reviewed label, the detail aid the rep carries, the disease education website, the peer-reviewed publications it sponsors, and the patient support programs it funds. Each channel is regulated, monitored, and auditable.
AI language models are none of those things.
They draw on an effectively infinite corpus of text — clinical trial registries, medical journal abstracts, patient forum posts, physician review sites, news coverage, and social media — and synthesize it into responses that carry the rhetorical weight of clinical authority. When a prescriber or patient asks an AI about a drug, they receive what feels like an expert answer. What they are actually receiving is a probabilistic synthesis of whatever the model was trained on, weighted by the internal architecture of the model itself.
For pharmaceutical brands, this creates three distinct risks that did not exist five years ago.
The first is label drift. AI models frequently describe drugs in ways that deviate from approved labeling — sometimes by understating indicated populations, sometimes by citing superseded safety data from older studies, sometimes by overstating comparative efficacy based on observational literature that never made it into regulatory submissions. A patient asking an AI whether a GLP-1 agonist is appropriate for weight loss when their primary diagnosis is type 2 diabetes may receive an answer that reflects the model’s training data from before the FDA’s expanded obesity indications took effect.
The second is competitive displacement. In a world where 73 percent of patients who consult a physician arrive having already researched their condition online, and where AI tools are rapidly displacing traditional search for health information, the AI model has become the first consultation. If that consultation consistently positions a competitor’s drug as the first-line standard of care — even subtly, even without explicit promotional intent — the prescribing conversation that follows is already tilted. Brand teams that don’t know what AI says about their product are flying blind into the highest-stakes conversation in their commercial funnel.
The third risk is regulatory exposure. The FDA’s Office of Prescription Drug Promotion has historically focused on what pharma companies say about their drugs. The agency is now actively examining what AI says — and how companies respond. In a draft guidance published in late 2023, the FDA signaled concern about pharmaceutical manufacturers using AI to generate content and the blurring of lines between promotional and non-promotional information in AI-mediated environments. More consequentially, the agency began asking drug companies whether they monitor AI representations of their products. Several companies had no answer.
How AI Learns to Talk About Your Drug — And Why It Gets Things Wrong
Understanding the risk requires understanding how AI models represent pharmaceutical information.
Large language models do not look things up. They generate responses based on statistical patterns learned during training. When a model describes the mechanism of action of a PD-1 inhibitor or lists the contraindications of a novel oral anticoagulant, it is not retrieving a stored document. It is generating text that, based on its training, is likely to appear in the context of that query. This distinction matters enormously for pharma marketers.
It means that the AI’s characterization of a drug is a function of the volume and character of text about that drug in the training corpus, weighted by the recency and apparent authority of those sources. A drug that has been covered extensively in high-quality clinical publications and discussed substantively on professional forums will be described differently than a drug that is newer, less studied, or primarily discussed in patient-facing consumer content.
It also means that the AI’s representation can diverge from approved labeling in ways that are difficult to predict and impossible to correct through traditional channels. You cannot issue a correction to a language model the way you can issue a letter to the editor. <blockquote> ‘By 2026, AI-mediated health queries will account for more than 40 percent of patient pre-consultation research, surpassing traditional search engines for drug and treatment inquiries for the first time.’ <cite>— Gartner Digital Health Forecast, 2024</cite> </blockquote>
The training data problem has a second layer. Pharmaceutical information on the internet is not evenly distributed. Legacy drugs with long histories of off-label use generate enormous volumes of patient forum discussion, physician commentary, and case study literature. That discussion frequently includes anecdotal reports, off-label indications, and comparative claims that would never survive regulatory review in a formal promotional context. When AI synthesizes this material, it often produces characterizations that reflect the messy reality of real-world prescribing rather than the clean, indication-specific descriptions in the label.
For brand managers, this is not an abstract concern. It means that the AI’s answer to ‘what is Drug X used for’ may include five indications, two of which are off-label, without distinguishing between them. It means that a head-to-head comparison between your drug and a competitor’s may cite a network meta-analysis with methodological limitations that your medical affairs team argued against in a published rebuttal — without mentioning the rebuttal.
Companies that track these characterizations systematically discover that AI models can hold a surprisingly stable, surprisingly wrong view of a product that has not been updated to reflect recent label changes or newly published efficacy data. One mid-sized oncology company discovered through DrugChatter monitoring that the leading AI platforms were consistently understating the overall survival benefit from its lead compound by describing data from the initial Phase II cohort rather than the updated Phase III readout, which had been published fourteen months earlier. The label had been updated. The AI had not caught up. In every query that followed, the drug was being described with data that materially undersold its efficacy.
The Regulatory Dimension: What the FDA Sees When It Looks at AI
The FDA’s approach to AI in pharmaceutical promotion is still developing, but the direction of travel is clear.
The agency has consistently interpreted the Food, Drug, and Cosmetic Act’s provisions on misbranding and misleading promotion broadly. Historically, this applied to materials a company created, distributed, or controlled. The emergence of AI creates pressure to extend that logic. If a company’s promotional content trains an AI model that subsequently makes misleading claims about that company’s drug to millions of users, does the company bear any responsibility? Legal opinion is divided. Regulatory risk is not.
What is not divided is the FDA’s view on a company’s obligation to know what is being said about its products in the marketplace. Under existing guidance, pharmaceutical manufacturers are expected to have systems in place to monitor promotional and non-promotional content about their drugs and to take corrective action when that content is inaccurate or misleading. The question of whether AI-generated content falls within that monitoring obligation has not been formally resolved, but several companies that have received Warning Letters in the past three years have discovered that ‘we didn’t know’ is not a defense the FDA finds compelling.
The European Medicines Agency has gone further. Its 2024 guidelines on digital health communication explicitly require that pharmaceutical companies assess the representation of their products in AI-mediated environments and establish correction protocols when those representations diverge materially from authorized product information. Companies operating in the EU market who are not doing this are already out of compliance.
Pharmacovigilance adds another layer of regulatory complexity. AI conversations about drugs frequently surface adverse event reports. A patient describing a side effect to an AI assistant, or asking whether a symptom is related to a medication, generates a conversation that may constitute a reportable adverse event under both FDA and EMA regulations. The company has no access to that conversation. But if a monitoring system like DrugChatter captures that the AI is generating responses that normalize or minimize an adverse event that is listed as a serious risk in the product label, the company has a pharmacovigilance obligation that begins from that detection.
The question regulators are now asking is not ‘did you create the misleading content?’ It is ‘did you know about it, and what did you do?’
Brand Share in the Age of AI: The Metric Nobody Is Measuring
Traditional pharmaceutical market research measures brand share through prescribing data, brand tracking studies, and promotional response analytics. These instruments were designed for a world in which the prescribing decision flowed from physician to patient through a relatively controlled information environment. AI has introduced a new variable: what the AI says when neither the company nor the physician is present.
Call this AI share of voice — the proportion of AI-generated responses about a therapeutic category that mention, favor, or position a given brand. It is not the same as traditional share of voice, which measures the volume of promotional activity. AI share of voice measures something more consequential: the probability that an AI will recommend, describe, or contextualize your drug in a way that is favorable when a patient or prescriber asks a relevant question.
This metric matters for two reasons.
The commercial reason is straightforward. Patients who have received an AI-mediated recommendation for a specific drug before they see their physician are significantly more likely to ask about that drug by name. Physicians who have used an AI tool to check dosing or interactions are more likely to have the drug’s profile salient when making prescribing decisions. Neither of these effects requires the AI to make an explicit recommendation. Simply describing a drug as the ‘most commonly used’ or ‘first-line option’ in a therapeutic category shapes the conversation that follows.
The equity reason is subtler but equally important. Smaller brands, recently approved drugs, and drugs that serve patient populations with lower digital literacy generate less training data. They are systematically underrepresented in AI responses. A new-to-market oncology drug that hasn’t yet accumulated the clinical publication footprint of the category leader will be described less accurately, less favorably, and less completely by AI models — not because of any bias in the model’s design, but simply because there is less data for the model to draw on. Brand teams for these drugs face a structural disadvantage in AI-mediated information environments that their marketing budgets and traditional promotional strategies cannot address.
DrugChatter’s monitoring infrastructure tracks both dimensions. It indexes AI representations of brands across the major platforms on a continuous basis, scores them for accuracy against current approved labeling, and identifies emerging patterns in how AI positions a brand relative to its competitive set. When a pattern changes — when, say, the AI begins describing a competitor’s drug as the ‘preferred option’ in a sub-indication where your drug has equivalent efficacy — the brand team sees it within days, not quarters.
Voice of the Patient, Mediated by Machine
The pharmaceutical industry has invested heavily in patient centricity over the past decade. Patient advocacy relationships, real-world evidence programs, patient-reported outcome measures — all of these are attempts to bring the patient’s actual experience of a disease and its treatment into the drug development and commercial process. AI introduces a radically new form of patient voice: the conversation a patient has with a machine.
These conversations are, in aggregate, the most comprehensive patient research data that has ever existed. Patients describe their symptoms without the inhibition they sometimes feel with physicians. They ask questions they feel embarrassed to ask in a clinical setting. They report side effects, describe treatment burden, express preferences, and articulate fears with a specificity that no focus group or claims database can match.
Pharmaceutical companies cannot access individual AI conversations — nor should they. Privacy considerations are both legally binding and ethically non-negotiable. But the patterns in those conversations are visible in the aggregate, and they constitute a form of patient intelligence that has no precedent.
When DrugChatter monitors the queries that patients and caregivers are asking AI models about a given drug, it reveals the real unmet needs in a patient population. A pattern of queries about injection site reactions in a subcutaneous biologic indicates a tolerability issue that may not be surfacing in clinical outcomes data. A pattern of queries about insurance coverage and copay assistance indicates an access friction that is costing the brand patients at the point of refill. A pattern of queries about switching from one formulation to another indicates competitive pressure that a traditional market research survey, designed around questions the company thought to ask, would never capture.
This is a fundamentally different kind of market research. It is not a sample; it is the population. It is not retrospective; it happens in real time. And it is not shaped by the questions a researcher designed; it reflects what patients actually want to know.
One company monitoring its type 2 diabetes franchise through a real-time AI query analysis platform discovered in early 2024 that a substantial portion of queries about its drug were coming from patients asking whether it could be used for weight management purposes. This was before any weight management indication had been filed. The queries were driven by organic patient interest, amplified by social media discussion and AI responses that had synthesized observational data on metabolic effects. The brand team had no visibility into this until the monitoring picked it up. When they did see it, they accelerated their real-world evidence publication strategy to ensure that the AI models synthesizing this category had accurate data to draw on — rather than leaving the narrative to chance.
The Competitive Intelligence Angle: What AI Says About Your Rivals
Pharmaceutical competitive intelligence has traditionally been a slow business. You waited for competitors to present at medical conferences, publish in journals, file regulatory documents, or show up in prescribing data. You monitored their promotional spend through industry tracking services. You interviewed physicians about their impressions of competitive products.
AI changes the competitive intelligence timeline. Because AI models synthesize competitive information continuously and can be queried at scale, they function as a real-time index of the competitive landscape as the information environment sees it. How does the leading AI describe your competitor’s drug compared to yours? What data does it cite when it discusses the head-to-head? Does it mention your compound’s safety advantage, or does it weight older tolerability concerns more heavily because those concerns generated more text in its training data?
These questions have commercial answers. Companies that systematically query AI models with the prompts their patients and prescribers are asking — and that compare the answers against their competitive positioning — gain a form of intelligence that no other monitoring system provides.
They also gain a predictive signal. AI models respond to changes in the information environment with a lag of weeks to months. When a competitor publishes strong Phase III data, the AI’s characterization of that drug shifts — but not immediately. Monitoring that shift allows brand teams to anticipate the prescribing environment before it changes, rather than responding after the damage has been done.
There is a second competitive dimension that is less intuitive but equally important. AI models are not neutral aggregators. They apply internal weighting to sources, respond to the way questions are framed, and can be influenced — within limits — by the character and volume of authoritative content that exists about a drug. Companies that publish clear, accessible, accurate content about their drugs, optimize their clinical publication strategy for machine readability, and ensure that their regulatory filings contain well-structured summaries of key efficacy and safety claims are investing in their AI representation. Companies that produce only dense, legally-hedged promotional material optimized for human reviewers are not.
What Pharma Has Gotten Wrong About AI Marketing
The pharmaceutical industry’s initial response to AI has followed a familiar pattern. Large companies assigned AI to their digital innovation teams, which built chatbots and content generation tools to improve internal efficiency. Some companies began experimenting with AI-generated promotional content, triggering immediate regulatory concern. Others treated AI as a technology capability question — a problem for IT and data science — rather than a brand strategy question.
All of these responses miss the point.
AI is not a tool pharmaceutical companies deploy. It is an environment in which pharmaceutical brands now live. Every major AI platform — and the dozens of smaller health-focused AI applications being deployed in clinical decision support, patient engagement, and formulary management — is constantly making representations about pharmaceutical products. Those representations affect prescribing behavior, patient adherence, and regulatory relationships. They are not under the company’s control. But they are not beyond the company’s influence, either.
The companies that are getting this right share two characteristics. They have built monitoring infrastructure — either through platforms like DrugChatter or through internal capabilities — that gives them real-time visibility into what AI says about their brands. And they have developed a response strategy that treats AI representation as a brand management challenge, not a technology project.
The response strategy has two components. The first is content investment. Ensuring that high-quality, accurate, well-structured information about a drug is widely available in the public domain — in clinical publications, in patient-facing disease education, in well-maintained medical information portals — is the only way to influence what AI models say about a drug. This is not a new principle; it is the logic that drove the pharmaceutical industry’s investment in medical affairs and scientific publication planning for decades. What is new is the urgency. In a world where AI is synthesizing information about your drug for millions of queries daily, the accuracy and completeness of the public information environment around that drug is a commercial variable, not just a medical affairs obligation.
The second component is regulatory engagement. Companies that have established monitoring capabilities are discovering that they have a material advantage in regulatory interactions. When an FDA reviewer asks whether a company is aware of misleading AI representations of its product, a company that can produce a systematic monitoring report demonstrating awareness and corrective action is in a fundamentally different position than one that cannot. This is not hypothetical — it has happened in Warning Letter responses and in pre-approval meetings.
How DrugChatter Solves the Monitoring Problem
The core challenge in pharmaceutical AI monitoring is not detecting what AI says. It is doing so at scale, across multiple platforms, with sufficient accuracy to distinguish clinically relevant deviations from label from minor stylistic variations, and doing it continuously enough to catch emerging patterns before they become brand problems.
DrugChatter addresses this by combining automated query generation, response collection, and NLP-based labeling analysis across the major AI platforms. The system generates queries that reflect the actual language patients and prescribers use when they ask AI about pharmaceutical products — not the sanitized, on-label phrasings that marketing teams test in focus groups, but the real-world questions that surface in patient forums, physician review sites, and health search queries. It then collects AI responses to those queries, scores them for alignment with current approved labeling, and identifies patterns in how competing drugs are characterized.
The output is a continuous brand intelligence feed that operates on a fundamentally different time scale from traditional market research. Where a quarterly brand tracking study tells you what physicians thought about your drug three months ago, DrugChatter tells you what AI said about your drug today — including whether that characterization has changed, in what direction, and across which platforms.
For pharmacovigilance teams, the platform flags AI responses that minimize or omit serious risks listed in the product label, generating documentation that is relevant to regulatory compliance. For medical affairs teams, it identifies gaps between the published evidence base and the AI’s characterization of that evidence — signaling where targeted publication or data dissemination efforts could close the accuracy gap. For brand managers, it tracks AI share of voice relative to the competitive set, providing a metric that no other commercial monitoring system currently captures.
The underlying architecture processes AI outputs through a comparison engine trained on regulatory labeling documents. When an AI describes a drug’s efficacy in terms that differ from the label claim — whether by overstating, understating, or shifting the indication — the system flags the deviation and classifies it by type and severity. This classification is the basis for the compliance workflow: determining whether a deviation requires corrective content investment, regulatory notification, or both.
The Medical Affairs Function Will Never Be the Same
Pharmaceutical medical affairs has historically operated as the boundary between promotional and scientific communication. Medical affairs teams managed the relationships with key opinion leaders, reviewed off-label inquiries from physicians, supervised publication planning, and ensured that the scientific record supporting a drug was robust enough to withstand regulatory and clinical scrutiny.
AI has expanded the scope of that function in ways that most medical affairs organizations have not yet absorbed.
When an AI model represents a drug’s clinical evidence to a prescribing physician, that representation is not under medical affairs supervision. It may be accurate. It may be outdated. It may overweight a secondary endpoint that the company’s publication strategy deliberately de-emphasized. It may fail to mention a contraindication that the medical affairs team worked hard to ensure was prominently communicated in clinical practice guidelines. The physician receives all of this without the context that medical affairs labored to provide.
The implication is that medical affairs must now think about the AI information environment as a core part of its mandate. This means ensuring that the publications program produces content that AI models can accurately synthesize — structured abstracts, clear primary and secondary endpoint hierarchies, explicit comparisons to relevant standards of care. It means building medical information resources that are designed for machine readability, not just human readers. It means monitoring what AI says about the scientific evidence and tracking whether that characterization shifts as new data becomes available.
It also means developing new capabilities in AI literacy within the medical affairs function. Understanding how large language models weight different types of sources, how training data recency affects characterization accuracy, and how the framing of clinical data in publications influences AI representation requires a form of expertise that most medical affairs teams do not currently have. Building it is now a competitive necessity.
What the Next Two Years Look Like
The pharmaceutical industry is approximately eighteen months behind where it needs to be on AI brand monitoring. The companies that are furthest ahead — mostly large-cap biotechs and specialty pharma organizations with sophisticated digital capabilities — are beginning to treat AI representation as a standard component of commercial launch planning. They query AI models before launch to establish a baseline characterization, identify accuracy gaps in the pre-launch information environment, and develop a content strategy designed to close those gaps before the drug reaches the market.
Most companies are not there yet. The majority of pharmaceutical brand teams still treat AI as something that happens in the background — a force they are vaguely aware of but have not built systems to address.
That will change, and it will change quickly. The catalyst will not be a voluntary strategic insight. It will be a Warning Letter, a product liability case involving an AI-mediated adverse event report, or a significant prescribing shift that a brand team traces back to an AI characterization that had been wrong for six months before anyone noticed.
The regulatory environment will accelerate the change. FDA’s Center for Drug Evaluation and Research has internal working groups examining AI in pharmaceutical promotion that will produce guidance within the next twelve months. The EMA requirements are already in effect. State attorneys general have begun examining consumer protection implications of AI health misinformation, including drug-related claims. The legal exposure for companies without monitoring capabilities will increase substantially over this period.
The commercial environment will do the same. As AI-mediated health queries continue to grow — and the growth rate, currently estimated at 60 percent year-over-year, shows no sign of decelerating — the fraction of the prescribing conversation that happens outside traditional promotional channels will increase. Every quarter that a brand team operates without visibility into that conversation is a quarter in which competitive displacement, label drift, and pharmacovigilance exposure accumulate undetected.
The pharmaceutical industry has survived many disruptions by adapting its commercial model. It adapted to managed care by building health economics capabilities. It adapted to direct-to-consumer advertising by building patient engagement infrastructure. It adapted to the internet by building digital marketing functions. Each adaptation took longer than it should have. The AI adaptation will need to be faster, because the speed at which AI is reshaping the information environment around pharmaceutical brands does not allow for gradual adjustment.
Building an AI-Ready Commercial Strategy
There is a practical framework emerging from the companies that are farthest ahead.
It begins with monitoring. Before a brand team can respond to AI representation, it needs visibility into what that representation is. This means deploying a systematic monitoring capability — DrugChatter or an equivalent — that queries AI platforms at scale with realistic patient and physician prompts and collects the responses. The monitoring program should cover at minimum the major general-purpose AI platforms (ChatGPT, Gemini, Claude, Perplexity), the health-specific AI applications deployed in clinical decision support and patient engagement, and the AI features being rolled into search engines that handle health queries.
The output of monitoring feeds two downstream functions. The compliance function reviews deviations from approved labeling and establishes a record of awareness and response. The brand intelligence function analyzes AI share of voice, competitive positioning, and patient query patterns to inform commercial strategy.
Content strategy comes next. Improving AI representation is fundamentally a content problem. The AI characterizes a drug based on what it has learned. Changing that characterization requires changing the information environment — producing well-structured clinical publications, accurate patient education content, clear and complete medical information resources, and regulatory submissions with machine-readable summaries. This is a long-cycle investment, but its effects compound over time. Companies that start now will have significantly better AI representation in two years than those that wait.
Regulatory engagement follows naturally. Companies with monitoring capabilities can provide regulators with documentation of their awareness and response. This documentation, which DrugChatter’s reporting infrastructure is designed to produce, is becoming a standard element of regulatory interaction in both the US and EU markets.
Finally, organizational alignment. AI brand monitoring is not a technology project. It sits at the intersection of medical affairs, regulatory, commercial, and legal functions. The companies that are doing it well have built cross-functional ownership — not a single team ‘responsible for AI’ but a shared accountability across the functions that the AI monitoring outputs touch.
Why This Is Actually an Opportunity
It would be easy to read the preceding analysis as a catalog of threats. AI as regulatory exposure, competitive displacement, pharmacovigilance liability. That framing is real but incomplete.
AI also creates capabilities that did not exist before.
A pharmaceutical company with real-time monitoring of what patients ask AI about its drug has access to patient intelligence that was previously unimaginable in its scale and granularity. It can detect safety signals emerging in patient experience conversations before they surface in formal adverse event reports. It can identify unmet needs in the patient population that are invisible in claims data. It can see competitive vulnerabilities in its own positioning and address them before they become prescribing patterns.
A pharmaceutical company that invests in the AI information environment around its drug — through publication strategy, patient education, and medical information resources designed for machine readability — builds a durable competitive advantage. The drug that is most accurately and favorably represented in AI is the drug that benefits from the first-mover advantage in every AI-mediated health query in its therapeutic category.
A pharmaceutical company that builds regulatory documentation of its AI monitoring program is not just protecting itself from liability. It is building a record of responsible digital health citizenship that will have increasing commercial and reputational value as AI oversight intensifies.
The companies that see AI as something to fear will respond reactively, slowly, and expensively. The companies that see AI as an environment to manage will build the capabilities now, when the competitive advantage is largest and the cost of building is lowest.
The AI conversation about your drug is happening right now, without you. The question is whether you’re listening.
Key Takeaways
AI has become pharma’s most powerful unmanaged stakeholder. AI platforms are making consequential representations about pharmaceutical products to millions of patients and prescribers daily, with no regulatory review, no company control, and no feedback loop to the brand team.
Label drift is a real compliance risk. AI models frequently describe drugs in ways that deviate from approved labeling — overstating indications, citing outdated safety data, or reflecting off-label use patterns from patient forums. Companies without monitoring capabilities have no way to detect or correct these deviations.
AI share of voice is the metric that will matter. Traditional prescribing and brand tracking data cannot measure the commercial impact of AI-mediated health queries. Platforms like DrugChatter provide continuous monitoring of how AI characterizes brands relative to their competitive set.
Regulatory exposure is growing and specific. The FDA and EMA are moving toward formal expectations that pharmaceutical companies monitor AI representations of their products and take corrective action when those representations are inaccurate. The ‘we didn’t know’ defense will not hold.
Voice of patient intelligence through AI query monitoring is unprecedented. The patterns in patient queries to AI models constitute the most comprehensive, real-time, unfiltered patient research data that has ever existed. Companies that monitor these patterns gain a form of commercial intelligence that no traditional market research instrument provides.
Content investment is the only lever that improves AI representation. Because AI models synthesize public information, improving their characterization of a drug requires improving the quality and accuracy of the public information environment — through publication strategy, patient education, and regulatory-quality medical information resources designed for machine readability.
The companies that act now have the largest advantage. The first movers in AI brand monitoring and AI-ready content strategy will build durable competitive advantages in AI share of voice that compound over time and that late movers will find expensive to overcome.
FAQ
Q: If AI models are trained on publicly available data, can pharma companies actually influence what AI says about their drugs?
A: Yes, but through indirect means. AI models weight sources by apparent authority and volume. A drug with extensive, well-structured peer-reviewed publication coverage, clear patient education resources, and regularly updated medical information portals will be characterized more accurately than a drug whose public information footprint consists primarily of regulatory documents and dense promotional copy. The lever is content quality and volume in machine-readable formats — which is why companies that approach AI representation as a medical affairs and publication strategy challenge, rather than a technology problem, are seeing better results. There is no way to directly edit an AI model’s weights, but there is a way to improve the information environment the model learns from. That work takes 12 to 18 months to show results, which is why starting now matters.
Q: How does AI monitoring differ from traditional social media listening for pharmaceutical brands?
A: Social media listening captures what people say about a drug in public digital conversations. AI monitoring captures what an AI says about a drug when asked — which is a different and more consequential data set. A social media post reaches the followers of the person who posted it. An AI response reaches every person who asks a similar question, across every platform that uses that model. The scale is different by orders of magnitude. The clinical authority that users attribute to AI responses is also different — people generally know that a social media post reflects one person’s opinion, while an AI response often reads as factual and comprehensive. The compliance implications are also distinct: a misleading social media post by a third party may or may not create regulatory exposure for a pharmaceutical company, but an AI representation that deviates from approved labeling creates documentation and response obligations regardless of who trained the model.
Q: What should a pharmaceutical company do if it discovers that a major AI platform is consistently misrepresenting its drug?
A: The response has several layers. Immediate documentation is the first step — creating a record of the deviation, its nature, and its severity, which DrugChatter’s reporting system supports directly. The regulatory affairs team needs to assess whether the deviation constitutes a materially misleading representation that triggers notification obligations under FDA or EMA guidelines. The medical affairs team needs to identify the source of the inaccuracy in the public information environment and develop a content strategy to address it — typically through targeted publications or updated patient education materials. Legal should assess whether the deviation creates product liability or consumer protection exposure. Direct engagement with the AI platform operator is sometimes appropriate, particularly where the deviation relates to safety information, but this is a newer and still-developing practice with variable results across platforms.
Q: How does pharmacovigilance intersect with AI monitoring?
A: Two distinct intersection points exist. The first is detection: AI query patterns can surface emerging adverse event signals from patient experience conversations that have not yet translated into formal adverse event reports. A pattern of queries asking whether a specific symptom is related to a drug is a pharmacovigilance signal, even if none of those queries constitute a formal report. The second is compliance: when an AI model provides responses that minimize or omit serious risks listed in a drug’s approved label, those responses may constitute pharmacovigilance-relevant information, and a company that is aware of them has monitoring and potentially reporting obligations. The regulatory framework for this intersection is still developing in the US, but the EMA’s 2024 digital health communication guidelines have begun to address it explicitly.
Q: Is there evidence that AI representation actually affects prescribing behavior?
A: Direct causal evidence is limited because no one has yet designed a randomized controlled trial to test it — which is itself revealing about how far behind the research base is relative to the phenomenon. What does exist is survey data showing that between 40 and 60 percent of patients who consult AI about a health question report that the AI response influenced what they discussed with their physician, and that a meaningful fraction of those patients report asking for a specific drug by name based at least partly on what an AI told them. On the prescriber side, surveys of physicians who use AI tools for clinical decision support show that AI responses influence medication selection in a significant minority of cases, particularly for newer drugs or complex dosing scenarios where the physician is less familiar with the evidence base. The effects are not large in absolute terms, but they operate on every query, which at scale translates to material prescribing influence.