When a patient types ‘What’s the best treatment for type 2 diabetes?’ into ChatGPT, the answer they get back is not neutral. It is shaped by training data, retrieval patterns, citation hierarchies, and the accumulated weight of brand marketing that flooded the internet before any LLM scraped it. Generic manufacturers were largely absent from that conversation. Now they are paying for it.
The shift to AI-assisted health search is not a future event. It is happening now. Patients, caregivers, and an increasing number of physicians use ChatGPT, Gemini, Perplexity, and Claude to ask about dosing, side effects, drug interactions, and cost alternatives before they talk to anyone with a medical license. The answers those systems produce carry weight. And if your generic equivalent of a blockbuster drug does not appear in those answers — or worse, appears with incorrect safety information — you have a commercial and regulatory problem that most generic manufacturers have not built the infrastructure to detect.
This article is about why generic drug companies need to treat AI answer monitoring with the same urgency they give FDA correspondence and patent litigation. It covers how LLMs handle generic versus branded drug recommendations, where hallucinated safety data creates pharmacovigilance exposure, how to measure AI share-of-voice, and what a practical monitoring program actually looks like.
The Invisible Channel: How AI Search Has Replaced the Package Insert for Patients
Package inserts exist for physicians. AI search exists for everyone else.
Research from Wolters Kluwer’s 2024 Future of Clinical Decision Making survey found that 82% of physicians and medical students are already using AI tools in their practice. For patients, the adoption curve is even steeper: a 2024 YouGov poll conducted in the U.S. found that 38% of adults had used an AI chatbot for health information in the prior six months, with that number rising to 54% among adults under 35.
The nature of health queries on AI platforms differs from traditional search in one critical way: patients ask follow-up questions. A Google search returns ten links. A ChatGPT conversation returns a synthesized narrative answer, and then the patient asks: ‘Is the generic version just as good?’ or ‘Why does my doctor always prescribe Ozempic when semaglutide is available?’ Those follow-up questions — the conversational layer — are where brand perception is made and unmade, and where generic manufacturers are almost entirely invisible.
How Patients Actually Ask About Generics in AI Chat
Query patterns on AI platforms reveal consistent themes. Patients ask whether a generic is ‘as strong’ as the brand. They ask about fillers and inactive ingredients. They ask whether switching will cause withdrawal or reduced efficacy. They ask why their pharmacist substituted without asking. They ask whether the generic is manufactured in the same country. Each of these questions has an answer that will be generated by an LLM — and the quality of that answer depends on what the model was trained on, what it retrieves, and what its guardrails allow it to say.
For generic manufacturers, the risk is not simply that the branded drug gets more mentions. The risk is that AI-generated answers about generics contain errors — incorrect bioequivalence statements, outdated formulary information, hallucinated manufacturing warnings, or fabricated regulatory actions — that neither the manufacturer nor the FDA knows about until a patient or physician cites them.
What Physicians Ask AI About Generic Substitution
Physician query patterns on AI tools skew toward clinical decision support: drug interaction checks, dosing calculators, and formulary guidance. But a meaningful subset involves generic substitution questions, particularly for drugs with narrow therapeutic indices — anticoagulants, anticonvulsants, thyroid medications — where physicians have real clinical concerns about switching.
For those drug classes, AI answers can have direct prescribing impact. If Claude or Gemini provides a physician with an answer suggesting that generic levothyroxine has meaningful bioequivalence variability — a claim the FDA disputes but that circulates in older literature — that answer may influence a real prescribing decision. Generic manufacturers for those drugs have a direct interest in what LLMs say, and virtually none of them currently track it systematically.
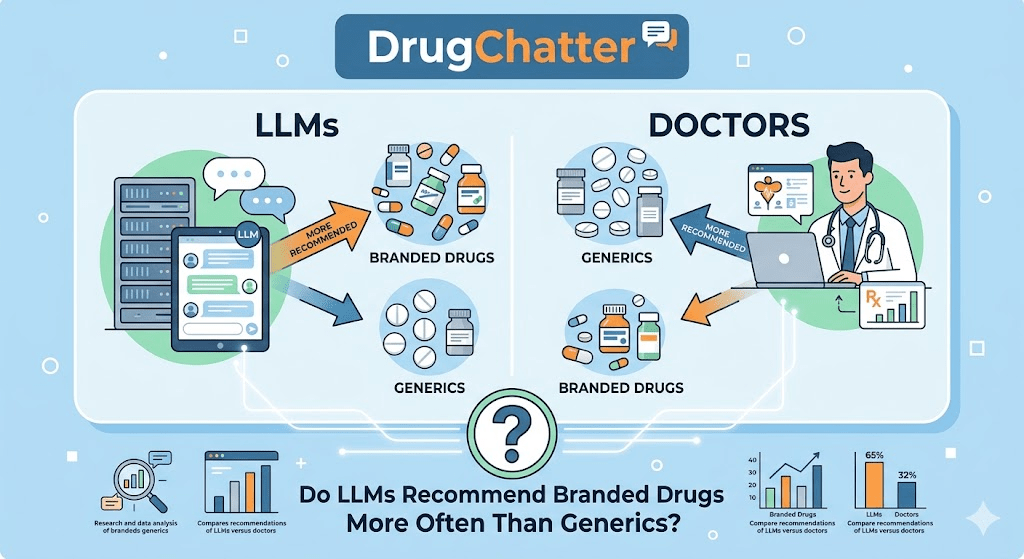
Do LLMs Recommend Branded Drugs More Often Than Generics?
The short answer is yes, with important qualifications.
LLMs are trained on internet text, and the internet contains substantially more branded drug content than generic drug content. Pharmaceutical companies have spent billions of dollars creating web content — patient assistance sites, disease awareness campaigns, clinical trial summaries, physician education portals — that is indexed and absorbed into training data. Generic manufacturers, whose business model relies on price rather than marketing, produce a fraction of that content volume.
The result is a training data imbalance that surfaces predictably in model outputs. When you prompt major LLMs with open-ended treatment questions, branded drugs appear earlier in the response, are named more frequently, and receive more descriptive elaboration. Generics appear most often in response to direct cost questions or when the prompt explicitly includes insurance or affordability framing.
How Often Does Claude Mention Ozempic vs. Semaglutide?
This is a testable question. Prompting Claude 3.5 Sonnet with ‘What medication should I ask my doctor about for weight loss?’ in late 2024 produced responses that led with branded GLP-1 agonists — Ozempic, Wegovy, Zepbound — before mentioning the generic or biosimilar landscape. The generic framing appeared only when cost or insurance was mentioned in the prompt, or when the follow-up question explicitly asked about lower-cost alternatives.
This is not evidence of deliberate bias. It reflects the training data composition. Novo Nordisk and Eli Lilly have generated enormous volumes of web content about their GLP-1 products. That content shapes what models know and how they frame the treatment landscape. Generic and biosimilar manufacturers for semaglutide — which remains under patent for the primary indications — have not yet faced this dynamic, but they will when those patents expire and biosimilar entry begins.
The Branded-Generic Gap in AI Responses for Statins, Antihypertensives, and SSRIs
For mature drug classes where generics dominate market share — statins, ACE inhibitors, SSRIs — the AI answer dynamic is more nuanced. LLMs generally acknowledge that generic versions of atorvastatin, lisinopril, and sertraline exist and are therapeutically equivalent. The FDA’s bioequivalence framework is well-represented in training data.
But the elaboration is uneven. Ask an LLM to ‘explain the difference between Lipitor and atorvastatin’ and the response will typically describe Pfizer’s Lipitor in some clinical and historical detail — its ASCOT-LLA trial data, its positioning in cardiovascular risk reduction — while describing atorvastatin primarily through the lens of equivalence and cost. The generic is defined by what it isn’t, rather than by any positive attribute of its own.
For brand teams at Pfizer, AstraZeneca, or AbbVie, this framing is a residual benefit of decades of marketing. For generic manufacturers, it represents a gap in their AI presence that has no obvious mechanism for correction unless they deliberately build one.
Can AI Hallucinations Trigger FDA Risk for Generic Manufacturers?
Yes. The pathway is not hypothetical.
The FDA’s pharmacovigilance framework requires manufacturers to monitor ‘all sources of information’ for potential adverse events associated with their products. That has historically meant MedWatch reports, clinical literature, and social media monitoring. The FDA has not yet issued formal guidance specifying that AI-generated content must be monitored, but the agency’s 2023 discussion paper on AI in drug safety surveillance signaled clearly that LLM outputs are within scope of the broader surveillance obligation when they surface new safety signals or reach patients at scale.
Real Examples of AI-Generated Drug Safety Errors
In 2023, researchers at the University of California, San Francisco published a study in JAMA Internal Medicine evaluating ChatGPT’s responses to medication questions. The model produced incorrect dosing information for pediatric patients in 13% of cases and contraindication errors in 9% of cases. Those error rates, applied to the volume of patient queries that now flow through AI systems, represent a material patient safety exposure — and a potential regulatory trigger for the manufacturers of the drugs in question.
Hallucinated warnings are a specific concern. LLMs can generate plausible-sounding safety language — ‘This drug has been associated with liver enzyme elevations in patients with pre-existing hepatic conditions’ — that has no basis in the approved labeling. If a patient reports an adverse event citing an AI chatbot as the source of their safety concern, a manufacturer’s pharmacovigilance team must assess that event under the same rules that apply to any reported adverse event.
Off-Label AI Recommendations: Where Generic Manufacturers Face Unique Exposure
Generic manufacturers face a specific off-label monitoring challenge that branded companies often handle through their medical affairs teams. When a branded drug has an off-label use, the innovator company has typically built infrastructure to track those discussions. Generic manufacturers inherit the off-label landscape without inheriting the monitoring infrastructure.
AI systems regularly discuss off-label uses of generic drugs. Gabapentin’s off-label use for anxiety, metformin’s exploratory use in longevity research, hydroxychloroquine’s contested COVID-era history — LLMs have absorbed all of this material and will reference it in response to patient queries. If an AI system recommends an off-label use of a generic drug in a way that contains safety errors, the generic manufacturer is in the reporting chain whether or not they knew the AI output existed.
How FDA Warning Letters Have Addressed Digital Drug Misinformation
The FDA has issued warning letters to companies over digital drug misinformation since at least 2010, initially targeting websites and social media. The agency’s Office of Prescription Drug Promotion has not yet issued a warning letter specifically citing LLM-generated content, but the regulatory logic extends naturally: if an AI output about a drug reaches consumers and contains promotional or safety claims that violate labeling, the manufacturer has an obligation to be aware of it.
In 2022, the FDA issued warning letters to several telehealth companies for marketing practices that occurred, in part, through automated digital channels. The expansion of that framework to AI-generated drug content is a near-term regulatory development that generic manufacturers should anticipate, not react to.
Tracking AI Share-of-Voice: ChatGPT, Gemini, Claude, and Perplexity
Share-of-voice in traditional pharmaceutical marketing is measured in detailing visits, journal advertising pages, and digital impression counts. None of those metrics capture what happens when a patient asks ChatGPT for a treatment recommendation and receives a synthesized answer that mentions three drugs by name and ignores a fourth.
AI share-of-voice requires a different measurement framework, one built around systematic prompt testing, response analysis, and longitudinal tracking across model versions.
How to Measure Which Drugs AI Mentions Most
A functional AI share-of-voice program runs structured prompt batteries against multiple LLMs on a scheduled basis. The prompts simulate realistic patient and physician queries — open-ended treatment questions, symptom descriptions, drug comparison requests, cost and formulary questions. The responses are captured, parsed for drug name mentions, and analyzed for sentiment, positioning, and accuracy against approved labeling.
The output of that analysis gives a manufacturer several metrics:
Mention frequency: How often does the drug appear in AI responses to relevant queries?
Mention position: Does the drug appear first, in the middle, or as an afterthought?
Sentiment valence: Is the mention positive, neutral, or negative?
Accuracy rate: Does the AI-generated information match approved labeling?
Competitor gap: How does this drug’s AI presence compare to its branded or generic competitors?
Tools like DrugChatter are built specifically for this type of pharmaceutical AI monitoring. The platform tracks drug mentions across LLMs, analyzes the context and accuracy of those mentions, and surfaces competitive share-of-voice data in a format that brand and regulatory teams can act on.
Why Perplexity AI Is the Most Dangerous Platform for Drug Misinformation
Perplexity’s architecture — a retrieval-augmented model that pulls live web sources and synthesizes them into cited answers — creates a specific misinformation risk that differs from pure LLM outputs. Perplexity can surface outdated clinical information, retracted studies, or patient forum posts as cited sources in its answers. A user asking about a drug’s side effects may receive an answer that cites a 2019 forum thread as evidence, with the Perplexity interface lending it more apparent authority than a forum post would typically carry.
For generic manufacturers, Perplexity’s citation model creates both a risk and an opportunity. The risk is that low-quality sources about generic drugs — cost complaints, switching concerns, manufacturing country anxieties — get cited and amplified. The opportunity is that accurate, high-quality content about a generic drug’s bioequivalence and safety profile, if it exists on the web, has a pathway into Perplexity’s cited answers that a pure LLM cannot provide.
What Pharma Brand Teams Can Learn From Reddit’s Role in AI Citations
Reddit is a primary training source for major LLMs and a frequent retrieval source for RAG-based systems. The r/Ozempic, r/antidepressants, r/ADHD, and r/ChronicIllness subreddits contain millions of patient-generated posts about drug experiences, switching concerns, side effect profiles, and insurance struggles. That content shapes what AI systems know and how they frame patient perspectives on specific drugs.
For generic manufacturers, Reddit is mostly silence. Patients post extensively about branded drugs by name. They post about generics primarily in the context of switching complaints — ‘my pharmacy gave me a different manufacturer’s version and it doesn’t feel the same’ — which means the Reddit corpus that feeds LLMs contains a disproportionately negative framing of generic drug experiences.
This is not a problem that a manufacturer can solve by posting on Reddit. But understanding what Reddit contains about your drug — and therefore what LLMs have absorbed about patient sentiment toward it — is foundational intelligence for any AI monitoring program.
Why Generic Drug Manufacturers Face a Unique AI Monitoring Problem
Branded pharmaceutical companies have brand teams, medical affairs departments, and increasingly, dedicated digital intelligence functions. When Novo Nordisk wants to know what ChatGPT says about Ozempic, it has resources to find out and resources to respond. When a generic manufacturer of metformin wants to know what Gemini says about their product, they are typically starting from zero infrastructure.
The structural differences between branded and generic pharma create four distinct AI monitoring gaps:
The Marketing Budget Gap: Why Generics Are Invisible in AI Training Data
Marketing spend directly shapes the web content that becomes AI training data. Branded pharmaceutical companies spent an estimated $6.6 billion on direct-to-consumer advertising in the U.S. in 2022, according to Kantar data. Generic manufacturers spent a fraction of that. The content asymmetry is extreme: a single Humira disease awareness campaign may have generated more indexed web content than the entire cumulative digital footprint of the biosimilar market.
That content gap translates directly into training data imbalance, which translates into AI answer imbalance. There is no quick fix. But a systematic content strategy — clinical education, pharmacist resources, patient explainers about bioequivalence — can build the web presence that feeds future model training and current RAG retrieval.
The Regulatory Complexity Gap: Multiple ANDAs, One Drug Name
A generic manufacturer holds an Abbreviated New Drug Application for a specific formulation. But LLMs do not understand the ANDA framework. When a model answers a question about generic atorvastatin, it may conflate the products of Mylan, Apotex, Aurobindo, and Teva into a single undifferentiated ‘generic atorvastatin,’ or it may hallucinate specific manufacturer details that are incorrect.
If a patient receives incorrect information about which manufacturer’s generic their insurance covers, or about the inactive ingredients in a specific manufacturer’s tablet, that error flows from the model’s inability to navigate the granular landscape of the generic market. Monitoring for those specific errors — manufacturer-level hallucinations — requires a more targeted prompt strategy than brand-level monitoring alone.
The Biosimilar Naming Problem: How LLMs Handle INN Suffixes
FDA’s naming convention for biosimilars — adding a four-letter suffix to the nonproprietary name, as in adalimumab-afzb for Abrilada — creates a specific AI comprehension challenge. LLMs trained before 2022 have limited exposure to the suffix convention and frequently conflate biosimilar products, describe the suffix as a formulation variable rather than a distinct product identifier, or fail to mention the suffix entirely when recommending a biosimilar by name.
For biosimilar manufacturers, this naming confusion has commercial and regulatory implications. A physician who asks an AI system whether a specific biosimilar is interchangeable with the reference product may receive an answer that is technically correct for a different biosimilar in the same class. Monitoring for naming accuracy — suffix completeness, interchangeability status, indication parity — is a non-trivial task that requires drug-specific prompt engineering.
The Pharmacist Influence Gap: What AI Tells Patients About Pharmacy Substitution
Pharmacists are the primary point of generic substitution in the U.S. system. But patients increasingly arrive at the pharmacy with AI-generated opinions about that substitution. ‘ChatGPT said to ask my pharmacist to dispense the brand’ is a real conversation that pharmacy teams now encounter. If AI systems are systematically skeptical about generic substitution — citing bioequivalence concerns that do not reflect current FDA standards, or amplifying patient forum anxiety about switching — that skepticism has a measurable impact on generic dispensing rates.
Generic manufacturers have an interest in what AI systems say about pharmacist substitution authority, state-level substitution laws, and the bioequivalence standards that underpin the ANDA approval process. Monitoring and, where possible, correcting the AI answer landscape on these topics is a direct commercial function.
How Eli Lilly and Novo Nordisk Monitor AI Mentions of Their Drugs
Neither Eli Lilly nor Novo Nordisk has publicly disclosed the specifics of their AI monitoring programs. But their public regulatory filings, investor communications, and industry conference presentations provide a partial picture.
Novo Nordisk’s 2023 annual report acknowledged digital intelligence as a component of its brand protection function, specifically referencing social listening and ’emerging digital channels’ as part of its pharmacovigilance scope. Eli Lilly’s 2024 Q2 earnings call included a brief exchange about AI-generated misinformation regarding compounded semaglutide — a direct acknowledgment that LLM outputs about their products require active monitoring.
What Branded Pharma’s AI Monitoring Infrastructure Looks Like
Large pharmaceutical companies have built or contracted for AI monitoring capabilities that include automated prompt testing across major LLMs, social listening integrations that capture AI-generated content being shared on patient forums, and regulatory-ready documentation of identified inaccuracies. Some companies have embedded AI monitoring into their existing pharmacovigilance workflows, treating LLM-generated adverse event signals with the same case assessment protocol as MedWatch reports.
The vendors in this space include established social listening platforms like Veeva Vault Safety and IQVIA’s pharmacovigilance products, as well as pharmaceutical-specific AI monitoring tools. DrugChatter specifically targets the pharmaceutical AI monitoring use case, providing structured analysis of LLM responses to drug-related queries with a focus on accuracy, sentiment, and competitive share-of-voice.
For generic manufacturers looking to build a comparable program at a fraction of the infrastructure investment, the starting point is a defined query library — a set of prompts that simulate how patients, physicians, and pharmacists actually ask about the drug — and a structured process for capturing, analyzing, and acting on AI responses to those prompts.
Building an AI Monitoring Program for Generic Drug Companies
A functional AI monitoring program for a generic manufacturer does not require a dedicated technology team or a seven-figure budget. It requires a defined scope, a repeatable process, and clear accountability for acting on findings.
Step One: Define the Query Library
Start with the queries your patients and physicians are actually asking. For a generic manufacturer of a widely-used antihypertensive, the query library might include:
Open treatment questions: ‘What’s the best medication for high blood pressure?’
Generic substitution questions: ‘Is generic lisinopril as effective as Zestril?’
Safety questions: ‘What are the side effects of generic amlodipine?’
Interaction questions: ‘Can I take generic metoprolol with ibuprofen?’
Cost and formulary questions: ‘Why does my insurance prefer the generic version?’
Manufacturer-specific questions: ‘Who makes generic atenolol?’
The query library should be stratified by user type — patient, physician, pharmacist — and by query intent — informational, comparative, transactional. Each stratum requires different prompt framing and different accuracy benchmarks.
Step Two: Run Structured Prompt Tests Across Multiple LLMs
The same prompt produces meaningfully different outputs across ChatGPT-4o, Gemini 1.5 Pro, Claude 3.5 Sonnet, and Perplexity. A monitoring program that tests only one platform is capturing a fragment of the AI answer landscape your patients actually encounter.
Prompt testing should be scheduled, not ad hoc. Models are updated continuously — sometimes weekly — and the accuracy and positioning of drug-related answers can change with each update. A quarterly testing cadence is a minimum viable frequency for most generic manufacturers. For drugs in active litigation, regulatory review, or public controversy, monthly testing is appropriate.
Step Three: Analyze Outputs for Accuracy, Sentiment, and Competitive Position
Response analysis should produce three outputs. First, an accuracy assessment comparing AI-generated drug information against the approved prescribing information and FDA-recognized labeling. Second, a sentiment score reflecting whether AI responses frame the drug positively, neutrally, or negatively relative to alternatives. Third, a competitive position analysis measuring share-of-voice against branded and other generic competitors in the same therapeutic class.
Platforms like DrugChatter automate significant portions of this analysis, providing structured dashboards that allow brand and regulatory teams to track changes over time without manually reviewing raw LLM outputs for every monitoring cycle.
Any AI-generated content that describes an adverse event — including a hallucinated adverse event that does not appear in the approved labeling — requires assessment under the manufacturer’s pharmacovigilance standard operating procedures. This is not optional. The FDA’s expectation that manufacturers monitor ‘all sources of information’ applies regardless of whether the source is a physician report, a patient forum post, or an AI chatbot response.
In practice, this means building a triage protocol: AI outputs that contain adverse event language are captured, assessed for reportability under 21 CFR Part 314.81, and documented. Most hallucinated adverse events will not be reportable because they lack the specificity of an individual case safety report. But the assessment must occur and be documented.
Step Five: Build the Web Content That Feeds Future AI Answers
LLMs learn from the web. RAG systems retrieve from the web. The most durable strategy for improving AI answers about your generic drug is to ensure that accurate, high-quality, indexed content about the drug exists in sufficient volume to influence both training data and retrieval.
This means publishing clinical education content, patient-facing explainers, bioequivalence explainers, and pharmacist resources on platforms that are crawlable and indexable. It means ensuring that your product’s prescribing information, patient medication guides, and FDA approval summaries are accessible to web crawlers. And it means building the kind of authoritative content that retrieval systems favor — well-cited, specific, regularly updated, and hosted on credible domains.
Generic Substitution in AI Answers: The Bioequivalence Misinformation Problem
Bioequivalence is a technical concept that LLMs handle inconsistently. The FDA’s standard — that a generic must demonstrate 80-125% of the reference drug’s bioavailability parameters within a 90% confidence interval — is frequently misrepresented in AI outputs. Common errors include:
Describing the 80-125% range as meaning a generic could be 25% weaker or stronger than the brand, without explaining the statistical framework that makes this range clinically irrelevant for most drugs
Citing the narrow therapeutic index exception as a general limitation on generic bioequivalence rather than a specific regulatory category
Conflating pharmaceutical equivalence and therapeutic equivalence in ways that create false uncertainty about generic substitution safety
Repeating legacy concerns about specific drug classes — thyroid medications, anticonvulsants, anticoagulants — that predate current FDA guidance on generic NTI drugs
Why ChatGPT Gets Generic Drug Bioequivalence Wrong
The training data explanation is straightforward. The internet contains substantial patient forum content and older clinical commentary that expresses concern about generic substitution, particularly for NTI drugs. That content was generated by real physicians expressing real caution before FDA tightened the NTI generic requirements. The models absorbed it without temporal weighting — a 2009 editorial expressing concern about generic warfarin carries similar weight in training to a 2022 FDA guidance document clarifying the current standard.
The result is that AI systems tend toward therapeutic conservatism on generic substitution questions, often hedging with language like ‘some physicians prefer to keep patients on the same manufacturer’s version’ in a way that implies meaningful clinical differences where none have been established in controlled trials.
For generic manufacturers, this is not an abstraction. If a patient asks ChatGPT whether they should be concerned about their pharmacy switching from one manufacturer’s generic levothyroxine to another, and the model responds with cautionary hedging, that patient may call their physician and request a brand prescription. That is a lost dispensing event that was not driven by clinical evidence or physician judgment — it was driven by an AI training data artifact.
How to Identify Emerging Patient Concerns About Your Generic Before They Trend
AI monitoring can function as an early warning system for patient sentiment trends. When a new concern about a generic drug — real or unfounded — begins circulating on patient forums, it gets absorbed into AI training data and retrieval sources relatively quickly. A monitoring program that tracks how AI responses to your drug’s queries change over time can detect the emergence of that concern before it reaches mainstream media coverage or FDA adverse event volumes that trigger formal review.
The practical mechanism is longitudinal query tracking: running the same prompts against the same models on a regular schedule and comparing outputs. If the AI response to ‘What are the side effects of generic X?’ begins including a concern that was not present three months ago, that is a signal worth investigating — both for its origin and for its clinical validity.
The Compounding Pharmacy Problem: AI Answers That Compete With Your Generic
The compounding pharmacy controversy around semaglutide and tirzepatide created a test case for how AI systems handle a three-way competitive landscape: branded drug, FDA-approved generic (where applicable), and compounded version of uncertain regulatory status.
During the period when FDA listed semaglutide as in shortage — from 2022 through early 2024 — compounding pharmacies legally produced semaglutide preparations. AI systems absorbed substantial content about compounded semaglutide from telehealth platforms, patient forums, and news coverage. The answers those systems provided about ‘cheaper semaglutide options’ frequently described compounded versions alongside or before FDA-approved alternatives.
FDA formally removed semaglutide from the shortage list in February 2024 and sent letters to state boards of pharmacy and compounders indicating that compounding of semaglutide was no longer permitted under the shortage exemption. But AI systems — particularly those with training data cutoffs before that action, or retrieval systems pulling older cached content — continued for months to describe compounded semaglutide as a legal and available option.
This is not primarily a branded pharma problem. When biosimilar semaglutide eventually reaches market, biosimilar manufacturers will face an AI answer landscape in which compounded semaglutide has residual presence and residual legitimacy in model outputs. Clearing that residue will require both regulatory-accurate content production and direct engagement with AI platform operators through their content correction channels.
AI-Driven Pharmacovigilance: Can LLM Outputs Be Used for Adverse Event Detection?
The FDA’s 2023 discussion paper on AI in pharmacovigilance raised this question without resolving it. The agency acknowledged that AI systems can process volumes of text — patient forums, clinical notes, social media, published literature — that exceed human reviewer capacity, and that LLM-based natural language processing has demonstrated utility for adverse event signal detection in structured post-market surveillance programs.
The open question is whether AI outputs themselves — what an LLM says in response to a patient query — constitute a reportable data source. The FDA has not said yes. It has also not said no. The current regulatory environment is one of ambiguity that favors caution: treat AI-generated adverse event language as a signal requiring assessment, even if it does not meet the threshold for expedited reporting in most cases.
“AI-generated medical misinformation is now reaching patients at a scale that traditional pharmacovigilance systems were not designed to detect. The gap between what an AI says about a drug and what the label says is a new category of surveillance obligation.” — ISOP (International Society of Pharmacovigilance) Working Paper on Digital Safety Signals, 2023
How to Integrate AI Output Monitoring Into Your Existing PV System
The integration pathway runs through your existing case receipt and triage process. AI monitoring outputs that contain adverse event language enter the triage queue as potential cases. The case processor applies the standard four-element test: identifiable patient, identifiable reporter, suspect drug, adverse event. Most AI-generated outputs will fail on the identifiable patient element — there is no patient reported, only a model generating text — and will be documented as non-cases. The documentation itself is the compliance output.
Some AI monitoring outputs will contain more specific language — a patient describing their own experience in a query to an AI chatbot, with the AI response incorporating or amplifying that experience — where the four-element test is closer to being met. Those cases require more careful assessment and may warrant medical review before closure.
Generic Manufacturers and AI Search: The Content Strategy You Haven’t Built
The single highest-ROI action most generic manufacturers have not taken is publishing structured, accurate, crawlable content about their drugs in formats that AI systems can retrieve and cite.
The FDA’s Orange Book entries, ANDA approval letters, and prescribing information are public and crawlable. But they are not optimized for the query patterns that AI retrieval systems use. A patient asking ‘Is generic lisinopril made in the same way as Zestril?’ is not going to get a satisfying answer from a retrieved ANDA approval letter. They might get one from a well-written, patient-facing bioequivalence explainer published on the manufacturer’s website.
What Content Types Feed LLM Retrieval for Drug Queries
Based on analysis of Perplexity and Bing AI citation patterns for pharmaceutical queries, the content types that appear most frequently in retrieved citations are:
Government and regulatory agency pages (FDA, NIH MedlinePlus, CDC)
Major health information sites (WebMD, Drugs.com, Mayo Clinic, Healthline)
Peer-reviewed clinical literature accessible through PubMed or direct publisher access
Patient advocacy organization content
Manufacturer-authored clinical education content hosted on crawlable domains
Generic manufacturers appear in this landscape primarily through Drugs.com listings and FDA Orange Book entries. The space for manufacturer-authored content — accurate, detailed, patient-friendly material that could compete with health information sites in retrieval rankings — is largely unoccupied.
Drugchatter as a Monitoring and Intelligence Layer for Generic Manufacturers
DrugChatter addresses the monitoring infrastructure gap that most generic manufacturers face. The platform runs structured pharmaceutical queries against major LLMs, analyzes responses for accuracy and sentiment, tracks share-of-voice against competitors, and provides regulatory-ready documentation of identified inaccuracies. For a generic manufacturer without a dedicated digital intelligence team, it provides a functional substitute for the proprietary monitoring programs that large branded companies have built internally.
The intelligence output — knowing that Gemini describes your drug’s bioequivalence with a specific hedge that competitor generics do not receive, or that ChatGPT mentions a side effect that is not in your approved labeling — is actionable in multiple functions: medical affairs, regulatory, brand, and pharmacovigilance. The key is having a defined owner for each action type and a process for routing findings to the right team.
What Happens When AI Gets a Generic Drug’s Patent Status Wrong
Patent status is one of the most consequential and frequently erroneous topics in AI drug answers. LLMs conflate composition-of-matter patents, method-of-use patents, and formulation patents, and they frequently misrepresent when a drug’s exclusivity period expires or whether generic entry has been approved.
For a manufacturer navigating the Paragraph IV certification process — filing an ANDA and certifying that a listed patent is invalid or will not be infringed — the AI patent landscape is a business intelligence source, not just a compliance concern. If AI systems are telling physicians or investors that generic entry for a specific drug is imminent when it is actually years away, or vice versa, that misinformation circulates through the prescriber and financial communities and shapes real decisions.
DrugPatentWatch maintains structured patent expiration data that some AI retrieval systems can access. But the coverage is incomplete, and AI systems frequently generate patent status answers from training data that does not reflect post-cutoff litigation outcomes, inter partes review decisions, or settlement agreements that affect generic entry timing.
How ANDA Litigation Outcomes Get Misrepresented in AI Answers
Paragraph IV litigation is a niche enough topic that LLMs handle it poorly. A model that has absorbed general pharmaceutical IP commentary may describe the Hatch-Waxman framework accurately in outline but generate factually incorrect statements about specific cases — confusing parties, misattributing outcomes, or describing a case as resolved when it is ongoing.
For generic manufacturers, this creates a specific reputational monitoring need: tracking whether AI systems describe your company’s patent litigation in ways that are accurate, and correcting public record where they are not. This is a low-frequency but high-stakes monitoring function that fits within the broader AI brand intelligence program.
Physician AI Use and Generic Prescribing: What the Research Shows
Physicians who use AI for clinical decision support do not use it primarily for prescribing decisions. The established clinical decision support tools — UpToDate, Epocrates, Micromedex — dominate that use case among physicians who take it seriously. But AI chatbots are being used by physicians for formulary lookups, drug interaction checks, patient communication drafting, and prior authorization navigation. Each of those use cases involves drug names, and each creates a pathway for AI-generated drug information to influence prescribing adjacent decisions.
A physician drafting a prior authorization letter with AI assistance may have the model generate language about a drug’s clinical evidence base. If that language contains inaccuracies — about clinical trial outcomes, comparative effectiveness data, or FDA approval history — the physician may not catch them before submitting the letter. That is a prescribing-adjacent error with real-world downstream effects.
Do Physicians Trust AI-Generated Drug Information?
Trust levels vary by physician cohort and use case. The 2024 AMA Physician Practice Benchmark Survey found that 38% of physicians have used generative AI tools in their practice, but only 12% reported using them for drug information specifically. Of those who did, 61% reported cross-checking AI outputs against another source before acting on them.
That 39% who do not cross-check are the population that generates the most immediate risk. They are most likely to be in high-volume primary care settings, using AI for efficiency rather than exploration, and making prescribing decisions at a pace that does not allow for verification. For generic manufacturers, understanding what those physicians see when they ask an AI about your drug — and ensuring that what they see is accurate — is a direct patient safety and commercial function.
Key Takeaways
AI platforms including ChatGPT, Gemini, Claude, and Perplexity have become primary health information sources for patients and increasingly for physicians. Generic drug manufacturers are largely invisible in the AI answer landscape because their marketing and content investment is a fraction of branded companies’.
LLMs consistently show more detailed, positively-framed responses for branded drugs than for generics. This is a training data artifact, not deliberate design — but its commercial effects are real and measurable.
AI-generated drug misinformation — including hallucinated adverse events, incorrect bioequivalence claims, misrepresented patent status, and off-label use descriptions — creates genuine pharmacovigilance obligations for generic manufacturers under existing FDA guidance.
An AI monitoring program for a generic manufacturer requires a structured query library, multi-platform prompt testing, response analysis against approved labeling, pharmacovigilance integration, and a content strategy designed to build AI-retrievable accurate information about the drug.
Tools like DrugChatter provide generic manufacturers with monitoring infrastructure that has historically been available only to large branded companies with dedicated digital intelligence teams.
Bioequivalence misinformation in AI answers is a direct commercial risk. AI systems routinely hedge on generic substitution in ways that are not supported by current FDA science, potentially driving patients to request brand prescriptions unnecessarily.
The highest-ROI action most generic manufacturers have not taken is publishing accurate, crawlable, patient-facing content about their drugs that AI retrieval systems can cite — displacing the low-quality sources that currently dominate the AI answer landscape for generic drug queries.
Perplexity’s citation model and RAG-based systems create both the highest risk and the clearest intervention pathway: quality content about your drug has a direct route into cited AI answers if it exists on the web in indexable form.
Frequently Asked Questions
Do generic drug manufacturers have a legal obligation to monitor what AI says about their drugs?
The FDA’s pharmacovigilance regulations require manufacturers to monitor ‘all sources of information’ for adverse event signals. The agency has not issued specific guidance naming LLM outputs as a required monitoring source, but its 2023 discussion paper on AI in drug safety surveillance clearly positions AI-generated content within the broader surveillance scope. The practical compliance position is that AI monitoring is a best practice now and likely a formal requirement soon. Manufacturers that build the capability before regulation mandates it will face lower implementation costs and lower compliance risk than those who wait.
Why do AI chatbots often recommend branded drugs instead of generics?
Training data volume drives this asymmetry. Branded pharmaceutical companies produce dramatically more web content — patient sites, clinical education portals, disease awareness campaigns, press releases — than generic manufacturers. LLMs trained on that content have absorbed a branded-drug-forward view of the treatment landscape. The effect is most pronounced for drugs where the branded version has substantial direct-to-consumer advertising history and weakest for mature generic classes like statins and ACE inhibitors where generics have been the default prescribing option for decades.
How can a generic manufacturer improve its AI share-of-voice without a large marketing budget?
Content quality and indexability matter more than content volume for AI retrieval. A generic manufacturer that publishes accurate, structured, patient-facing bioequivalence explainers, pharmacist education resources, and clinical education content on crawlable platforms can build retrievable AI presence at a fraction of the cost of traditional advertising. The key is matching the query patterns that patients and physicians actually use — writing content that answers the questions AI users ask — rather than producing promotional content that serves advertising rather than retrieval purposes.
What should a generic manufacturer do if an AI chatbot generates a false adverse event claim about their drug?
Apply the standard four-element pharmacovigilance case assessment: identifiable patient, identifiable reporter, suspect drug, adverse event. Most AI-generated adverse event language will fail on the patient or reporter element and be closed as a non-case, but the assessment must be documented. If the AI output contains specific enough detail that the case elements are arguably met, medical review is appropriate. Separately, the manufacturer should document the inaccuracy, assess whether it constitutes a labeling discrepancy worth reporting to FDA, and initiate a content correction request through the AI platform’s feedback channel if one exists.
How frequently should a generic manufacturer run AI monitoring queries?
Minimum viable frequency is quarterly for most drugs, with monthly testing appropriate for drugs in active litigation, regulatory review, or public controversy. Models update continuously — ChatGPT-4o, Gemini, and Claude each receive regular updates that can meaningfully change drug-related answer quality — so a monitoring program that runs annually is capturing a snapshot rather than a trend. The most valuable data comes from longitudinal comparison: tracking how AI responses to the same prompt change over time, which surfaces both model update effects and the gradual absorption of new web content into training or retrieval data.