When a patient asks ChatGPT whether they should take Ozempic or Wegovy, they are not reading your brand’s prescribing information, your FDA-approved label, or anything your medical affairs team approved. They are reading a probabilistic reconstruction of medical knowledge assembled from a training corpus that may be two years old, contaminated with Reddit threads, and completely indifferent to your co-pay card program.
That’s the new reality for pharmaceutical brand teams. The channel has changed in a way that PR, digital marketing, and regulatory affairs were not built to address. And the companies that treat AI search as “just another digital channel” will find out — often through an adverse event report or a competitor’s market share gain — that it is not.
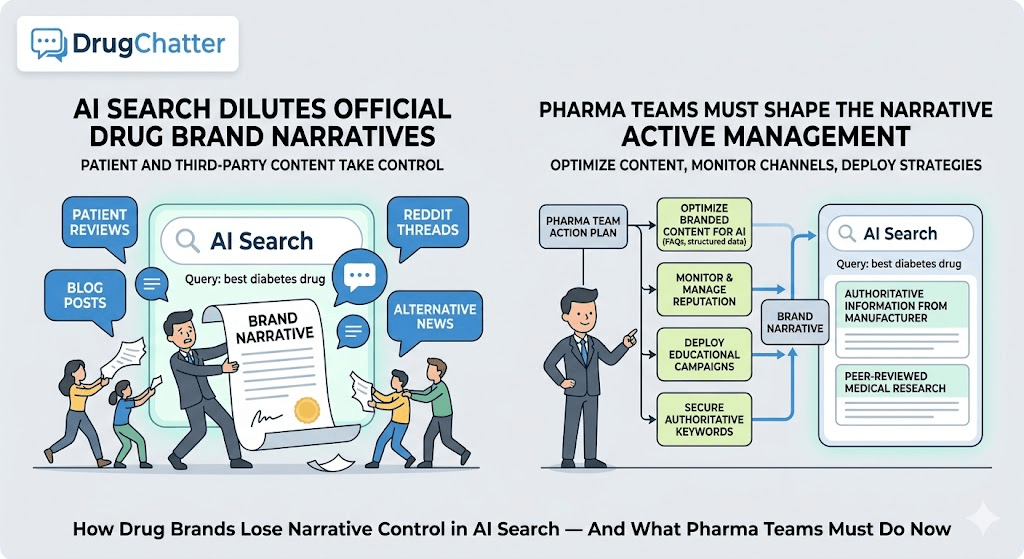
This article is a detailed map of how that loss of control happens, what it costs, and what a serious pharmaceutical organization should do about it. It covers real drugs, real regulatory risk, real litigation patterns, and the emerging infrastructure — including tools like DrugChatter — that forward-looking brand teams are using to monitor AI-generated drug narratives before they do damage.
The Invisible Channel: Why AI Search Is Now a Drug Information Source
Search behavior is shifting faster than pharma’s monitoring infrastructure. Perplexity AI reported over 100 million monthly active users by late 2024. ChatGPT crossed 200 million weekly active users in August 2024, according to OpenAI. Google’s AI Overviews, rolled out to U.S. users in May 2024, now appear above traditional organic results for a significant share of health-related queries.
Patients are asking these systems drug questions. Physicians use them for quick literature checks. Caregivers ask about pediatric dosing. Cancer patients ask about off-label protocols. Rare disease patients — who have often exhausted conventional information sources — ask about compassionate use and unapproved indications with a directness they would never bring to a physician consultation.
The AI systems answer all of these questions with uniform confidence regardless of whether their information is accurate, current, or appropriate to the clinical context.
How Patients Actually Ask About Drugs in AI Search
Internal query analysis from conversational AI platforms reveals that patients rarely phrase drug questions the way a physician would. They ask things like: “Can I take metformin if I have kidney problems?”, “Does Keytruda work for lung cancer if you’ve never smoked?”, “What happens if I miss a dose of Eliquis?”, and “Is there a cheaper version of Dupixent that does the same thing?”
These are not queries that map cleanly onto prescribing information or even patient education materials. They are conversational, anxious, and often contain embedded assumptions that the AI system will either correct or reinforce — with no way for the brand team to know which is happening at scale.
Why Physicians Use ChatGPT for Drug Lookups Despite Warnings
A survey published in JAMA Network Open in early 2024 found that 38% of physicians had used a large language model (LLM) for a clinical reference task in the preceding three months. Of those, fewer than half said they verified the output against a primary source. The reasons given were consistent: time pressure, perceived convenience, and an assumption that the AI would flag uncertainty when it existed.
It does not reliably do that. LLMs are architecturally optimized to produce fluent, confident text. Expressing uncertainty requires specific prompting techniques most physicians do not use. The result is that a physician may receive a hallucinated drug interaction presented with the same confident register as a verified clinical fact.
What AI Hallucinations Mean for FDA Compliance and Pharmacovigilance
The FDA’s adverse event reporting framework was designed around a clear information chain: a patient or physician experiences a problem, reports it to the manufacturer or directly to MedWatch, and the manufacturer includes it in its aggregate pharmacovigilance submissions. AI search breaks this chain in several ways simultaneously.
Can AI Hallucinations Trigger FDA Risk? The Regulatory Answer Is Yes
FDA regulations under 21 CFR Part 314 require manufacturers to report adverse events regardless of where they learn about them. The question of whether AI-generated medical misinformation about a drug constitutes a reportable adverse event is not yet resolved by formal guidance, but the directional interpretation from FDA’s Digital Health Center of Excellence is that companies have an obligation to monitor digital channels — including AI-generated content — for safety signals.
The practical problem is that an AI system telling a patient that Jardiance can cause severe hypoglycemia (it carries low hypoglycemia risk as a monotherapy; that is largely a sulfonylurea profile) could cause a patient to discontinue a beneficial therapy. The harm is real. The signal may never appear in a FAERS submission because the patient never told anyone what they read, and the AI system has no adverse event reporting obligation whatsoever.
How Hallucinated Drug Safety Claims Spread — and Why They Persist
LLMs are trained on static datasets, and their outputs can reflect medical understanding that was accurate when the training data was collected but has since been superseded. A drug that received a new black box warning after a model’s knowledge cutoff will continue to be described without that warning until the model is retrained or fine-tuned.
The problem compounds because AI outputs influence downstream content. When a patient asks ChatGPT about a drug, screenshots the response, and posts it to a Facebook health group or a Reddit community, that AI output becomes part of the social web — potentially re-ingested by the next generation of training data. Hallucinations can become self-referential.
Real FDA Warning Letters and the AI Monitoring Gap
FDA has issued warning letters for drug promotion on social media since at least 2009. The agency’s letters to companies like Duchesnay (for a Kim Kardashian Instagram post about Diclegis in 2015) established that promotional content in digital channels is subject to the same rules as traditional advertising. Those precedents did not anticipate AI-generated content, but they establish the agency’s appetite for digital channel enforcement.
The more immediate risk for brand teams is not that FDA will issue a warning letter about an AI chatbot’s output — the regulatory framework for that remains unclear. The risk is that an AI system’s misrepresentation of a drug’s safety profile reaches enough patients to create a real-world harm signal, and the company cannot demonstrate it was monitoring for it.
“Pharmaceutical companies spend billions monitoring clinical trial safety signals, but most have zero systematic visibility into what the AI systems their patients use every day are saying about their drugs.” — Cited from a 2024 McKinsey & Company report on digital health monitoring gaps in pharmaceutical brand management.
Share-of-Voice in the Age of AI: How Brands Are Being Outranked by Generics
Brand teams have spent years building share-of-voice metrics in traditional search. The concept is well-understood: what percentage of relevant queries surface your brand versus a competitor’s? AI search makes this harder in two directions at once.
Do LLMs Recommend Generic Drugs More Often Than Branded Versions?
The short answer is: frequently, yes — and for reasons that are partly logical and partly structural.
LLMs are trained on a corpus that heavily includes medical literature, clinical guidelines, and educational content. That content, especially from academic and governmental sources, tends to prefer generic names. A training corpus that includes ClinicalTrials.gov, PubMed, and UpToDate will learn to say “semaglutide” before it says “Ozempic” or “Wegovy,” and it will learn to say “adalimumab” before it says “Humira” or “Hadlima” or “Hyrimoz.”
This has direct commercial implications. A patient who asks “what is the best injection for weight loss” may receive an answer that discusses semaglutide’s mechanism without ever mentioning that Novo Nordisk’s Wegovy is the only semaglutide product with an FDA-approved indication for chronic weight management. An AI answer might equally recommend compounded semaglutide — a category that FDA has taken enforcement action against — without flagging the regulatory distinction.
How Often Does Claude Mention Ozempic vs. Wegovy vs. Compounded Semaglutide?
This kind of query-level brand monitoring is precisely what platforms like DrugChatter are built to answer. The tool systematically queries LLMs with the types of questions real patients and physicians ask, then tracks how frequently specific branded drugs are mentioned, in what clinical contexts, alongside what competitors, and with what accuracy relative to approved labeling.
The output looks like a share-of-voice report, but it is built from the actual outputs of AI systems rather than from click data or impression counts. Brand teams can see, for instance, that when a patient asks about GLP-1 options for type 2 diabetes, Ozempic appears in 74% of AI responses while Victoza appears in 31% — or whatever the actual distribution turns out to be at any given moment.
Tracking Branded vs. Generic AI Mentions: What the Data Looks Like
The monitoring challenge is scale. There are not five or ten ways a patient might ask about a drug. There are thousands. Someone asking about Humira might phrase the query as “biologic for rheumatoid arthritis,” “TNF inhibitor for psoriasis,” “self-injection for Crohn’s,” or “biosimilar vs. Humira cost difference.” Each query path may surface a different set of brands with different frequency and accuracy.
Systematic AI monitoring requires building a query library that approximates the full range of how real users ask about a therapeutic area, then running those queries regularly across multiple AI platforms to detect shifts over time. A brand that was well-represented in GPT-4o responses may find its visibility drops after a model update — with no notice and no explanation from the AI provider.
The Patient Sentiment Problem: What AI Is Telling Patients About Side Effects
The side-effect profile of a drug as described by an AI system can diverge from the approved label in ways that range from inconsequential to clinically dangerous. Understanding that divergence — and its direction — matters for brand strategy, pharmacovigilance, and regulatory affairs simultaneously.
Why ChatGPT Gets Drug Side Effects Wrong — And How Often It Happens
A 2023 study published in JAMA Internal Medicine evaluated ChatGPT’s responses to questions about 20 common medications and found factual errors in approximately 26% of responses, with side-effect descriptions being the most common error category. A separate analysis by researchers at the University of California San Francisco found that ChatGPT’s drug interaction warnings were accurate for well-studied pairs but frequently missed interactions involving newer drugs approved after the model’s training cutoff.
The errors are not random. LLMs tend to hallucinate in predictable directions: they overstate side-effect severity for drugs with high media coverage of adverse events, they understate risks for drugs with sparse training data, and they conflate the profiles of drugs within the same class. A model trained heavily on news coverage of Vioxx may apply an outsized cardiovascular risk frame to other COX-2 inhibitors, even those with a different clinical profile.
How Patient Communities on Reddit Shape AI Drug Narratives
Reddit is a major source of training data for LLMs, and the pharmaceutical communities on Reddit — r/diabetes, r/ChronicPain, r/MultipleSclerosis, r/Ozempic, r/BreastCancer — are large, active, and full of first-person adverse event reports that never made it into FAERS.
When an LLM learns from these communities, it absorbs the dominant narrative. If r/Ozempic in a given training window was dominated by posts about “Ozempic face” and gastrointestinal side effects, the model will over-index on those experiences relative to the clinical trial population. If r/Humira contains an active thread about biosimilar switching concerns, the model may reflect those concerns as though they are clinically established.
This is not entirely bad — patient-reported outcomes in AI training data can surface real signals that clinical trials undercount. But it is uncontrolled. The brand team has no visibility into what the AI learned from Reddit, and no mechanism to correct the record when a community narrative diverges from the clinical evidence.
Can AI Outputs Be Used for Pharmacovigilance? What Regulators Are Watching
The EMA has been more forward-leaning than FDA on this question. Its 2023 guidance on AI in the context of medicine noted that AI-generated signals from patient-facing digital channels could be considered “unvalidated sources” within the pharmacovigilance framework — meaning they warrant review, but do not automatically trigger reporting obligations.
Several large pharmaceutical companies, including Roche and Pfizer, have disclosed in investor materials that they use AI tools to monitor social media for adverse event signals. Extending that monitoring to AI-generated content is a logical next step, and companies that can demonstrate systematic AI monitoring will be in a stronger regulatory position than those that cannot if an AI-related safety issue ever results in enforcement attention.
How Eli Lilly, Novo Nordisk, and Other Companies Are Responding to AI Narrative Risk
The GLP-1 category is the clearest case study in pharmaceutical AI narrative risk because no drug class has more consumer AI query volume. Ozempic and Wegovy have become household words. Mounjaro and Zepbound are gaining fast. The AI systems are flooded with queries, and the responses vary dramatically across platforms.
What Eli Lilly’s Brand Team Faces When AI Discusses Tirzepatide
Mounjaro (tirzepatide) received FDA approval for type 2 diabetes in May 2022. Zepbound, the same molecule, received approval for chronic weight management in November 2023. This creates a common AI error pattern: systems trained before November 2023 may describe tirzepatide only in the diabetes context, missing the weight management indication entirely. Systems trained after that date may conflate the two products, applying the diabetes dosing information to weight management queries or vice versa.
Lilly’s brand teams must monitor for both directions of error simultaneously, across a half-dozen AI platforms, in multiple languages, against a competitive set that includes Novo Nordisk’s two products, compounded alternatives, and a pending pipeline of competitors from Amgen, Pfizer, and others.
How Novo Nordisk Manages AI Share-of-Voice for Semaglutide Products
Novo Nordisk’s AI brand management challenge is distinct. The company has two approved semaglutide products for different indications (Ozempic for type 2 diabetes, Wegovy for weight management), a third semaglutide formulation pending oral bioavailability work, and a biosimilar threat horizon that is further out than most biologics due to the complex manufacturing involved.
The risk for Novo Nordisk is that AI systems collapse the distinction between products. A patient who qualifies for Wegovy under FDA’s obesity indication — a BMI of 30 or above, or 27 with a comorbidity — may ask an AI system for information and receive an answer that discusses Ozempic, which is not labeled for that population in the same way. Novo Nordisk has been active in media engagement and physician education about the distinction, but that investment is partly undermined every time an AI system conflates the two.
Legal Exposure: When AI Drug Misinformation Meets Product Liability
The litigation frontier here is genuinely novel. No U.S. court has yet ruled on whether a pharmaceutical manufacturer has liability exposure for harm caused by AI-generated misinformation about its drug. But the legal architecture that could support such a claim exists, and plaintiffs’ attorneys are aware of it.
The theory would not require proving the company created the AI content. It would require proving the company knew or should have known that AI systems were systematically misrepresenting its product’s safety profile, and that the company failed to take reasonable steps to correct the record. The “knew or should have known” element is where proactive AI monitoring either creates or eliminates exposure.
A company with documented, systematic monitoring of AI outputs — and documented efforts to correct or contextualize misinformation through available channels — is in a fundamentally different position than a company that conducted no monitoring and took no action.
Off-Label AI: What Happens When Patients Ask About Unapproved Uses
Off-label promotion is one of the most heavily regulated areas of pharmaceutical marketing. A sales representative cannot discuss an unapproved use. A journal advertisement cannot imply it. An exhibit at a medical conference cannot feature it without specific carve-outs under FDA’s rules on scientific exchange.
How LLMs Discuss Off-Label Drug Uses — Without Any FDA Constraints
LLMs face none of those constraints. They are not pharmaceutical manufacturers, and they are not promoting drugs. They are generating text. When a patient asks Claude or Gemini whether low-dose naltrexone helps with fibromyalgia, or whether metformin has anti-aging properties, or whether high-dose ivermectin might treat a particular viral infection, the AI system will answer based on its training data — which likely includes a substantial volume of content discussing all of those uses.
The brand team for naltrexone cannot send a warning letter to Anthropic. The question is what they can do, which requires understanding the scope of the problem first. How often are off-label uses being discussed? In what clinical contexts? With what accuracy? Is the AI citing legitimate preliminary research or fringe advocacy? These are answerable questions with the right monitoring infrastructure.
Monitoring AI for Off-Label Promotion Risk: What Pharma Medical Affairs Must Track
Medical affairs teams have a specific interest in off-label AI monitoring that differs from the commercial interest. A medical affairs team’s job includes scientific exchange — the provision of accurate, balanced information about the full scientific evidence base for a drug. When AI systems present off-label uses inaccurately (either overstating their evidence base or dismissing well-developed preliminary evidence), the medical affairs function has an interest in understanding the scope of that misrepresentation.
The monitoring question for medical affairs is: what does the AI claim the evidence says about our molecule in unapproved indications, and is that characterization accurate? The answer to that question shapes medical information responses, physician outreach, and in some cases publication strategy.
The Competitive Intelligence Angle: Reading AI Outputs Like a Market Research Report
AI search outputs are, among other things, a form of market intelligence. The AI systems synthesize what the internet believes about a drug, a company, and a therapeutic area. That synthesis — if properly analyzed — tells you things that traditional market research often misses.
How to Analyze AI Drug Recommendations for Competitive Positioning
The core exercise is competitive query testing. Take the ten most common queries a patient in your therapeutic area would ask, run them across ChatGPT, Gemini, Claude, and Perplexity, and document the responses. Note which drugs are recommended, in what order, with what supporting rationale, and with what competitive context. Run the same exercise for physician-facing queries.
The output of this exercise — done systematically and repeatedly — is a competitive landscape map that reflects how AI systems position your drug relative to alternatives. It tells you whether AI is treating your drug as first-line or second-line, whether it is framing your drug’s side effect profile as better or worse than competitors, and whether it is recommending switching to generics or biosimilars.
What Pharma Brand Teams Can Learn From Reddit AI Citations
Some AI systems — particularly Perplexity AI and the search-augmented versions of ChatGPT and Gemini — cite their sources. When those citations point to Reddit, patient forums, or advocacy sites, they reveal something valuable: the AI is treating patient-generated content as authoritative information, and the specific threads cited tell you which community narratives are being amplified into AI responses.
A brand team monitoring these citations can identify, for example, that a specific Reddit thread describing an adverse event that did not make it into clinical trial data is being cited in AI responses to physician queries. That is a pharmacovigilance signal wrapped in a competitive intelligence package.
Which Drugs Are Most Frequently Mentioned by AI — And Why It Matters for Pipeline Planning
AI mention frequency is not entirely correlated with clinical importance or market share. It is correlated with media coverage, patient community activity, and the breadth of a drug’s presence in published literature. A drug that generated substantial controversy — a safety recall, a high-profile litigation, a celebrity endorsement — will be over-represented in AI responses relative to its actual clinical footprint.
For pipeline planning, this creates an interesting signal. Drugs and mechanisms that are heavily discussed in AI — even if that discussion is negative — have established patient awareness. A drug entering a category where AI systems already generate high-volume, accurate responses may have a different launch trajectory than one entering a category where AI systems draw a blank or answer with competitor products.
Building a Pharmaceutical AI Monitoring Program: The Practical Architecture
The monitoring function this article has been describing does not exist as a mature organizational capability at most pharmaceutical companies. Some have pilot programs. Some have assigned the problem to digital teams that lack the regulatory context to act on what they find. A smaller number have built or acquired dedicated infrastructure.
What a Real AI Brand Monitoring Stack Looks Like for Pharma
A functional pharmaceutical AI monitoring program needs four components working together: a query library, a testing infrastructure, an analysis layer, and a response workflow.
The query library is a curated set of questions representing the full range of how patients, caregivers, and physicians ask about the drugs in your portfolio. It needs to cover indication queries, safety queries, dosing queries, competitive queries, off-label queries, cost queries, and access queries. For a large portfolio, this can be thousands of queries.
The testing infrastructure runs those queries against multiple AI platforms on a regular schedule — daily for high-priority brands, weekly for others — and captures the outputs with metadata: which platform, which model version, which date. Model updates change outputs without announcement, so longitudinal tracking is the only way to detect shifts.
The analysis layer compares outputs against approved labeling, flags safety discrepancies, tracks mention frequency, and identifies competitive patterns. This is where tools like DrugChatter provide structured analytical infrastructure rather than requiring teams to build and maintain it themselves.
The response workflow defines what the organization does when it finds a problem. This is the hardest part, because the options are limited. You cannot issue a takedown notice to an AI system for describing your drug inaccurately. What you can do includes: flagging inaccuracies through AI platform feedback mechanisms, updating your own digital properties so they are more likely to be cited as authoritative sources, engaging medical education channels to counter specific misconceptions, and documenting your monitoring activity for regulatory purposes.
How DrugChatter Supports AI Share-of-Voice Tracking for Branded Drugs
DrugChatter is designed specifically for pharmaceutical AI monitoring. The platform queries LLMs at scale with drug-relevant prompts, tracks mention frequency across platforms, compares AI outputs to approved labeling, and provides brand teams with the kind of structured reporting they are accustomed to from traditional social listening platforms — but applied to the AI channel specifically.
The platform’s pharmacovigilance integration allows medical affairs and drug safety teams to flag AI-generated adverse event claims for review under existing FAERS processes. This is not a perfect solution to the regulatory gap around AI-generated drug information, but it represents the current state of the art for companies that need to demonstrate systematic monitoring.
How to Set Up AI Drug Monitoring Without a Six-Figure Tool Budget
For companies without immediate access to dedicated platforms, a minimal viable monitoring program has three elements. First, designate a monitor — someone in medical affairs or brand who runs a weekly sweep of 20 to 30 priority queries across three AI platforms and logs the outputs in a structured document. Second, build a discrepancy protocol — a documented process for what happens when an AI output contradicts approved labeling, including who reviews it, what the escalation path looks like, and how it is documented for regulatory purposes. Third, connect the monitoring to pharmacovigilance — ensure that the drug safety team sees AI-generated adverse event claims and has a defined process for triaging them.
This will not produce the same analytical depth as a dedicated platform, but it creates the documented diligence that matters for regulatory and legal purposes, and it builds the organizational muscle for a more sophisticated program later.
The AI Search Engine Landscape: ChatGPT, Gemini, Perplexity, and Claude Compared for Pharma
Not all AI platforms present the same risk profile for pharmaceutical brands. Understanding how each system works — and how it handles medical information differently — is prerequisite knowledge for building an effective monitoring program.
How ChatGPT Handles Drug Information Queries Differently Than Gemini
ChatGPT (GPT-4o) and Gemini (Google’s 1.5 Pro and Ultra family) both answer drug questions, but their knowledge architectures differ in ways that matter for pharmaceutical monitoring.
ChatGPT in its standard form draws on a training corpus with a cutoff that OpenAI updates periodically. Its search-augmented mode (which queries Bing) adds real-time information but introduces citation variability. For a brand team, this means a drug approved after ChatGPT’s training cutoff may be described incorrectly in standard mode but accurately in search-augmented mode — creating inconsistency depending on how the user accesses the product.
Gemini has tighter integration with Google’s search infrastructure, which means it more often cites and reflects authoritative medical sources — FDA drug databases, NIH resources, peer-reviewed journals. This is double-edged: Gemini may be more accurate on established drugs, but it also reflects Google’s index, which means the quality of a brand’s digital footprint directly shapes what Gemini says about it.
Why Perplexity AI Is Especially High-Risk for Drug Misinformation Monitoring
Perplexity AI presents a specific monitoring challenge because it cites sources for every claim, creating an appearance of rigor while the underlying source selection may reflect fringe or outdated content. A Perplexity response about a drug’s side effects might cite a 2019 case report from a low-impact journal alongside a 2024 FDA label update, presenting both with equivalent authority.
For pharmaceutical brand teams, Perplexity monitoring requires not just tracking what the AI says, but tracking what it cites. A systematic review of Perplexity citations for a drug reveals which information sources the system treats as authoritative — and whether those sources are the ones you would choose.
Claude’s Approach to Drug Information: Cautious, Citation-Conscious, Still Fallible
Anthropic’s Claude tends to be more conservative in medical contexts than GPT-4o or Gemini, more frequently directing users to consult healthcare professionals and flagging uncertainty. This makes it less likely to produce confidently stated hallucinations about drug safety, but it does not eliminate the risk. Claude will still reflect training data biases about generic versus branded drug preferences, and its knowledge cutoff creates the same lag problems as other systems for recently approved drugs or newly identified safety signals.
For pharmaceutical brand teams, Claude’s relative caution is an argument for monitoring it alongside, not instead of, other platforms. The AI with the most market share is the one that matters most for patient exposure, regardless of which one is most accurate.
LLM Search Optimization for Pharma: What Brand Teams Can Do to Influence AI Outputs
Traditional SEO involves optimizing content so search engines surface it in response to queries. The analogous challenge for AI search is sometimes called Generative Engine Optimization (GEO) or LLM Search Optimization (LSO). The mechanics are different, and the pharmaceutical regulatory constraints add complexity that does not exist in consumer sectors.
How Pharmaceutical Content Strategy Affects AI Drug Recommendations
LLMs learn from text. The text they learn from shapes their outputs. For pharmaceutical brands, this means that the quality, quantity, and structure of publicly available content about a drug — on the brand’s own properties, in medical literature, in regulatory documents, in physician education materials — shapes how AI systems describe that drug.
Content strategy for AI visibility starts with auditing what exists. Does the FDA label appear in a format that AI systems can readily process? Are prescribing information highlights structured as machine-readable text? Do the brand’s patient education materials describe approved indications with enough specificity that AI systems learning from them will produce accurate outputs?
These are not primarily SEO questions. They are questions about the quality of the information environment that AI systems train and operate in, and they have a direct bearing on whether AI descriptions of a drug are accurate.
Building a Medical Content Moat: Authoritative Sources AI Systems Prefer
Pharmaceutical companies have a structural advantage in one area: they have access to the most authoritative information about their drugs that exists. The challenge is making that information available in formats that AI systems can learn from and cite.
FDA-cleared full prescribing information, peer-reviewed publications from company-sponsored clinical trials, plain-language patient guides submitted to and reviewed by FDA — these are all sources that AI systems should ideally treat as authoritative. Building a content infrastructure that makes these sources accessible, well-structured, and frequently updated is the most defensible long-term strategy for AI narrative management.
Why Medical Affairs Must Own AI Search Strategy — Not Just Digital Marketing
The natural home for pharmaceutical AI monitoring is not the digital marketing team. The digital marketing team does not have the clinical and regulatory expertise to evaluate whether an AI output is medically accurate. The natural home is medical affairs, in close partnership with drug safety and regulatory affairs.
Medical affairs teams already own scientific exchange, medical information responses, and pharmacovigilance signal detection. AI monitoring is a natural extension of all three functions. The challenge is that medical affairs teams are not typically resourced for continuous digital channel monitoring, and the gap between what is happening in AI and what medical affairs teams are aware of is currently very large.
The Regulatory Future: How FDA and EMA Are Approaching AI Drug Information
Neither FDA nor EMA has issued comprehensive guidance on pharmaceutical companies’ obligations with respect to AI-generated drug information. Both agencies are aware of the issue and have signaled that guidance is in development.
What FDA’s Digital Health Center of Excellence Has Said About AI Drug Monitoring
FDA’s Digital Health Center of Excellence (DiHCoE) has published discussion papers on AI in health that address the general framework for AI safety monitoring without specific reference to AI-generated drug information in patient-facing AI systems. The agency’s 2023 draft guidance on AI-enabled device software functions provides regulatory architecture for AI tools used in clinical settings, but does not address consumer AI chatbots that patients use for drug information.
The regulatory gap is real, and it is likely to persist for two to three years as the agency develops frameworks. In the interim, companies should be guided by analogy: FDA’s existing framework for monitoring social media for adverse events, which was established in guidance documents in 2014 and 2017, provides the closest model. That framework requires systematic monitoring, documented processes, and pharmacovigilance integration. Applied to AI, it suggests the same.
EU AI Act Implications for Pharmaceutical AI Monitoring in Europe
The EU AI Act, which entered into force in August 2024, classifies certain AI systems used in healthcare as high-risk, with corresponding obligations for transparency, accuracy, and auditability. Consumer-facing AI chatbots that respond to medical queries may fall under these provisions depending on how they are positioned and deployed.
For European pharmaceutical companies, the EU AI Act creates both a compliance obligation and a monitoring rationale. If AI systems discussing your drug’s safety profile qualify as high-risk under the Act, the operators of those systems have disclosure and accuracy obligations. Monitoring what those systems say — and being able to document that monitoring — becomes part of your company’s due diligence in the European market.
Will FDA Require Pharmaceutical Companies to Monitor AI Mentions of Their Drugs?
No formal requirement exists today. The likelihood that one will emerge in the next five years is high, based on the agency’s existing framework for digital channel monitoring and the directional signals from its AI guidance work. Companies that build monitoring infrastructure now are investing in a capability they will likely need regardless of whether it becomes mandatory, and they are developing the organizational knowledge to execute it well before the regulatory deadline creates urgency.
The Misinformation Cost: Quantifying What AI Narrative Loss Actually Means
The business case for pharmaceutical AI monitoring ultimately rests on quantifying the cost of not doing it. This is not easy, because the causal chain between AI misinformation and patient or commercial outcomes is difficult to trace. But the components of that cost are identifiable.
How AI Drug Misinformation Drives Patient Abandonment and Non-Adherence
Medication adherence is already a major commercial and clinical problem. An estimated 50% of patients with chronic conditions do not take medications as prescribed, with non-adherence costing the U.S. healthcare system over $300 billion annually, according to data from the Network for Excellence in Health Innovation.
AI-generated misinformation about side effects is a direct driver of non-adherence. When a patient asks an AI system about their medication and receives an exaggerated or inaccurate side-effect profile, some percentage of those patients will discontinue therapy, reduce doses without guidance, or delay starting a prescribed medication. The share of non-adherence that AI misinformation now contributes is unknown, but it is growing as AI query volume grows.
Can AI Misinformation About a Drug Create Product Liability Exposure?
The product liability theory that could attach to a pharmaceutical company for AI-generated misinformation about its drug is still hypothetical. But the legal landscape around AI liability is moving fast. The FTC has taken enforcement action against companies that made materially false or misleading statements through AI systems. Class action law firms in the pharmaceutical sector are actively exploring AI narrative claims.
The strongest defense against these claims is documented monitoring and documented response. A company that can show it tracked AI outputs, identified inaccuracies, took available steps to correct them, and escalated safety-relevant discrepancies to appropriate regulatory channels is substantially better protected than one that has no monitoring record at all.
Key Takeaways
AI search platforms — ChatGPT, Gemini, Perplexity, Claude, and search-augmented AI tools — have become major drug information sources for patients and physicians, with no obligation to comply with FDA promotional standards or pharmacovigilance requirements.
LLMs systematically under-represent branded drugs relative to generics, reflect training data biases from Reddit and patient forums, and describe drug safety profiles that may lag FDA label updates by a year or more.
The off-label and safety hallucination risks are not theoretical — documented studies show error rates in AI drug responses approaching 26%, with side-effect descriptions being the most common failure category.
FDA’s adverse event monitoring requirements apply to all information channels, and companies that cannot demonstrate systematic AI monitoring will face increasing regulatory and legal exposure as AI query volume grows.
The competitive intelligence value of AI monitoring is real and underutilized: AI outputs reveal competitive positioning, patient concern patterns, and off-label discussion trends that traditional market research often misses.
Medical affairs — not digital marketing — is the appropriate organizational owner for pharmaceutical AI monitoring, given the clinical and regulatory expertise required to evaluate and act on AI output discrepancies.
Platforms like DrugChatter provide pharmaceutical brand teams with structured AI share-of-voice tracking, label accuracy comparison, and pharmacovigilance integration that enables proactive rather than reactive AI narrative management.
Companies building AI monitoring infrastructure now are ahead of likely mandatory requirements and in a stronger position for the EU AI Act compliance obligations already in force.
FAQ: Pharmaceutical AI Monitoring and Drug Brand Narrative Management
What is AI share-of-voice monitoring for pharmaceutical brands, and how is it different from traditional social listening?
Traditional social listening tracks what people say about a drug on Twitter, Reddit, or patient forums. AI share-of-voice monitoring tracks what AI systems — ChatGPT, Gemini, Perplexity, Claude — say about a drug when queried. The two channels are related (AI systems learn from social content) but distinct. An AI system may reflect a narrative that peaked on social media two years ago even if current patient sentiment has shifted. AI monitoring requires querying the systems directly and systematically, rather than listening to what humans post about them.
How should pharmaceutical companies handle an AI hallucination about a drug’s safety profile?
The immediate step is documentation: capture the exact output, the platform, the model version, the date, and the query used to elicit it. Then compare against approved labeling to characterize the nature and severity of the discrepancy. If the hallucination involves an adverse event or safety claim, escalate to drug safety for pharmacovigilance triage. For platform correction, most major AI providers have feedback mechanisms that can flag inaccurate information, though there is no guarantee of correction or timeline. Longer-term, investing in authoritative content infrastructure — well-structured FDA-cleared information that AI systems can cite — is the most durable corrective approach.
Can FDA hold a pharmaceutical company responsible for what an AI chatbot says about its drug?
Not under current regulatory guidance, which does not address AI-generated drug information created by third-party AI platforms. However, FDA’s existing framework for adverse event monitoring requires companies to report safety information they learn about through any channel, including digital channels. If an AI system is generating content that could cause patient harm, and the company knows about it, there is a credible argument that reporting obligations attach. The safer position is to treat AI-generated safety discrepancies as pharmacovigilance signals requiring review, consistent with how social media adverse events are handled under FDA’s 2014 and 2017 social media guidance.
Which AI platform presents the highest misinformation risk for pharmaceutical brands — ChatGPT, Gemini, or Perplexity?
Each platform presents a different risk profile. ChatGPT’s risk is highest for recently approved drugs and label updates that postdate its training cutoff; standard mode responses may lack current safety information. Gemini’s risk is highest when a brand’s digital footprint is weak, because Gemini’s outputs track its search index quality. Perplexity’s risk is distinctive because it cites sources, creating apparent authority for potentially outdated or fringe references. Comprehensive monitoring should cover all three, plus Claude and any emerging AI platforms gaining patient query volume. Monitor by query type, not just by platform.
How do LLMs decide whether to recommend a branded drug versus a generic — and can pharmaceutical companies influence that decision?
LLMs reflect the distribution of their training data. Medical literature, clinical guidelines, and educational content — which are heavily weighted in LLM training corpora — systematically prefer generic names. Brands can influence AI outputs by producing more high-quality, accessible content using their brand names in medically appropriate contexts: structured prescribing information, patient education materials, sponsored publication summaries, and FDA-approved digital resources. The more an AI system’s training and citation data includes authoritative branded content, the more likely it is to surface branded drug names accurately. This is a long-horizon investment, not a quick fix, and it works best when the content infrastructure is built proactively rather than reactively.