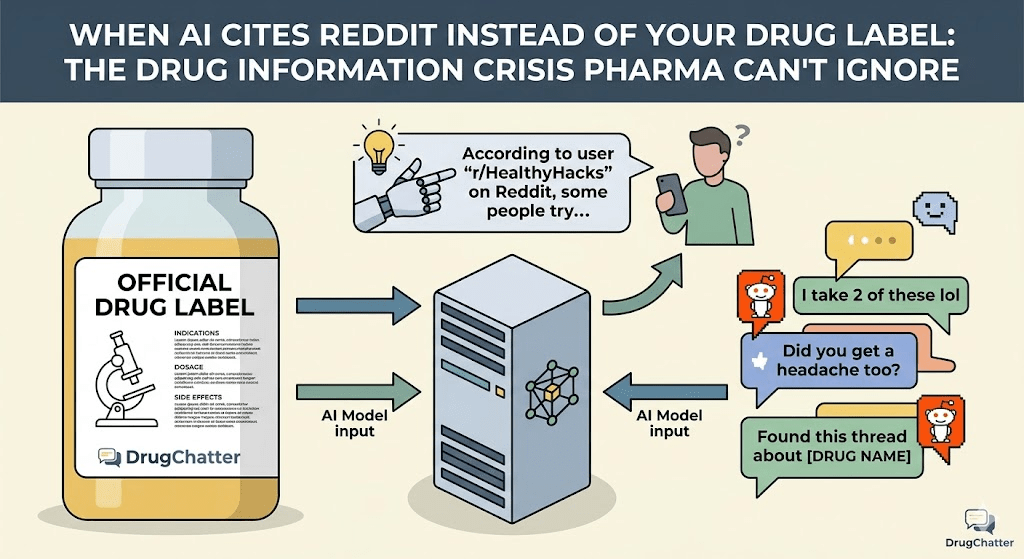
A patient types a question into ChatGPT: “Can I take metformin and ibuprofen together?” The AI answers in seconds — fluent, confident, and occasionally wrong. The response may draw from a 2019 Reddit thread in r/diabetes, a defunct health blog, or a forum post written by someone who confused their own dosing regimen with medical advice. The FDA-approved drug label, the prescribing information, the REMS documentation — none of it may surface at all.
This is not a hypothetical. It is the current operating reality of AI-powered health search, and it is happening at scale.
Across ChatGPT, Google Gemini, Perplexity, Microsoft Copilot, and dozens of smaller AI assistants, patients and caregivers are asking drug questions and receiving answers that are often sourced from the least reliable corners of the internet. The pharmaceutical industry — which spent decades constructing labeling infrastructure, adverse event reporting pipelines, and brand compliance systems — now faces a channel where none of those systems apply.
The risk is not abstract. When AI systems amplify Reddit-sourced drug misinformation, they create pharmacovigilance gaps, expose manufacturers to regulatory scrutiny, and distort the share-of-voice dynamics that brand teams have spent years managing.
This article examines how AI search systems source drug information, why Reddit and patient forums dominate LLM outputs, what regulatory exposure this creates for pharma companies, and how forward-thinking brand and medical affairs teams are beginning to monitor and respond.
How AI Systems Actually Source Drug Information
Why LLMs Don’t Default to FDA Labels
The intuitive assumption is that an AI trained on the entire internet would naturally weight authoritative medical sources — FDA.gov, PubMed, prescribing information — above everything else. That assumption is wrong, and understanding why matters if you want to grasp the scope of the problem.
Large language models are trained on massive corpora of text scraped from across the web. The weighting is not primarily determined by source credibility; it is determined by volume, link density, semantic relevance to the query, and recurrence across documents. Reddit posts about Ozempic outnumber FDA label passages about semaglutide by orders of magnitude. Patient testimonials on r/loseit, r/diabetes, and r/GLP1 are verbose, emotionally resonant, and cross-linked across dozens of threads. FDA labels are terse, technical, and rarely quoted at length in consumer-facing content.
The result: when a patient asks an LLM about Ozempic nausea, the model has been trained on a much larger signal from patient forums than from Novo Nordisk’s prescribing information. The output reflects that imbalance.
What Retrieval-Augmented Generation Changed — and Didn’t
Some AI systems, including Perplexity and the web-browsing version of ChatGPT, use retrieval-augmented generation (RAG) — meaning they fetch live web pages to supplement their base training before composing an answer. This was supposed to improve accuracy. It partially has. But it has also introduced a new problem: the AI now cites sources, and those sources are often Reddit, Drugs.com user reviews, WebMD comment sections, and health blogs with no medical editorial oversight.
Perplexity, in particular, frequently surfaces Reddit threads in its answer citations for drug-related queries. A search for “does Jardiance cause UTIs more often in women” will often return a cited answer that blends a clinical trial summary with anecdotal posts from patient forums — presented in the same confident, synthesized prose.
The patient reading the answer has no reliable way to distinguish which part came from the prescribing information and which part came from a forum post written by someone who had a bad experience and self-reported it online.
The Role of Web Crawl Bias in Pharmaceutical Queries
Search-augmented LLMs rank pages using a combination of signals: semantic match to the query, page authority, freshness, and user engagement metrics. For pharmaceutical queries, the pages that score highest on engagement — time on page, shares, backlinks — tend to be patient experience narratives, not regulatory filings.
A 2023 study published in JAMA Internal Medicine found that health information on Reddit was rated as more readable and more personally relatable than information from the CDC or NIH, which correlated with higher sharing rates. Readability and relatability are exactly the signals that AI retrieval systems optimize for. The FDA label for warfarin may be authoritative, but it is not readable in the way a Reddit post titled “My experience with Coumadin almost killed me — here’s what no one told me” is readable.
That difference in content character has real consequences for what AI systems serve as health guidance.
The Reddit Drug Information Problem: Real Examples
How r/diabetes Shapes What AI Says About Metformin
Metformin is one of the most prescribed drugs in the world. It has a well-established safety profile, an FDA label that has been refined over decades, and extensive clinical literature. It is also one of the most discussed drugs on Reddit, with active communities across r/diabetes, r/diabetes_t2, r/loseit, and r/PCOS.
When you query several major LLMs with questions like “does metformin cause B12 deficiency,” the answers vary significantly — not because the clinical evidence varies, but because the models weight different source pools. The FDA label and package insert do include a note on B12 deficiency monitoring. Some LLM outputs include this. Others, drawing more heavily from patient forum content, frame the B12 issue as something doctors routinely “miss” or “don’t warn you about” — a narrative frame that originates in patient advocacy forums, not clinical literature.
The difference matters. One framing prompts appropriate monitoring. The other erodes physician trust and positions a safe, effective drug as a hidden danger.
GLP-1 Drugs and the Off-Label Dosing Information Spreading Through AI
The GLP-1 receptor agonist class — Ozempic, Wegovy, Mounjaro, Zepbound — has generated more AI-mediated drug discussion than perhaps any other drug class in history. The overlap between obesity medicine, type 2 diabetes management, and lifestyle content has produced an enormous Reddit and TikTok corpus that LLMs have absorbed in training.
Multiple investigations by health journalists and researchers have documented that LLMs, when asked about Ozempic dosing, frequently describe off-label dosing strategies — including higher doses than approved, faster titration schedules, and combination approaches — that originate from posts in communities like r/Ozempic and r/WegovyWeightLoss. These communities have produced genuinely useful patient support, but they have also produced a substantial volume of self-experimentation content that should carry no clinical weight.
When that content shapes AI outputs, and when patients act on those outputs, the result is a pharmacovigilance event that no one in the traditional surveillance chain is positioned to catch.
Eliquis and Bleeding Risk: When Reddit Caution Becomes AI Misinformation
Eliquis (apixaban), the Bristol Myers Squibb and Pfizer anticoagulant, has a loyal and vocal patient community online. Patients on anticoagulation therapy are highly engaged health information seekers — the stakes of missed doses or drug interactions are immediately tangible.
Patient forums and Reddit threads about Eliquis contain extensive community-sourced guidance about bleeding risk management, dietary restrictions, and what to do in case of a missed dose. Some of this guidance aligns with prescribing information. Some of it does not. Recommendations about fish oil, NSAIDs, and minor procedures circulate in ways that are sometimes accurate and sometimes inconsistent with current clinical guidance.
When AI systems synthesize this content without weighting by regulatory authority, they produce outputs that blend accurate FDA-label language with community-sourced workarounds. For a patient managing anticoagulation, that blend is not a minor inconvenience. It is a potential adverse event.
Can AI Hallucinations Create FDA Regulatory Risk for Drug Companies?
The Pharmacovigilance Gap in AI-Generated Outputs
Under 21 CFR Part 314 and FDA guidance on postmarketing safety reporting, pharmaceutical manufacturers have defined obligations when they receive information about adverse drug experiences — including through the internet and digital media. The FDA’s 2014 guidance on social media monitoring clarified that manufacturers are expected to monitor owned channels and respond to adverse event signals.
AI-generated drug content exists in a regulatory gray zone that the FDA has not yet fully addressed. When ChatGPT states that a drug causes a side effect not listed in the FDA label — drawing on anecdotal Reddit reports rather than clinical data — is the manufacturer obligated to report? The answer is currently unclear, but the trend in FDA enforcement is toward broader, not narrower, surveillance obligations.
What is clear is this: if a manufacturer’s pharmacovigilance team is not monitoring AI outputs about their drugs, they are operating with a systematic blind spot. AI systems are now a primary channel through which patients and caregivers encounter drug safety information. Treating them as outside the surveillance perimeter is increasingly difficult to justify.
FDA Warning Letters and the Expanding Definition of Promotional Content
The FDA Office of Prescription Drug Promotion (OPDP) has issued warning letters in cases where promotional content — including social media content — made off-label claims or minimized risk information. The question of whether AI-generated content that references a branded drug constitutes promotional activity, and who bears responsibility for it, is one that pharmaceutical regulatory affairs teams are actively debating.
The risk scenario is specific: a pharma company’s own AI-powered chatbot, or a third-party AI tool integrated into a patient-facing service, generates a response about the company’s drug that omits required safety language or implies efficacy beyond the approved indication. Under current FDA interpretation, that output may constitute misbranding or an off-label promotion, regardless of the fact that it was AI-generated.
The FDA has not yet issued formal guidance on AI-generated promotional content as of mid-2025, but the agency has signaled in multiple public forums that existing promotional regulations apply to AI-generated content. Companies that assume AI outputs fall outside traditional regulatory frameworks are assuming incorrectly.
EMA Parallel: How European Regulators Are Framing AI Drug Information Risk
The European Medicines Agency has been more proactive than the FDA in framing AI-generated health content as a regulatory concern. The EMA’s 2023 workplan on artificial intelligence explicitly identified the spread of AI-generated drug misinformation as a signal monitoring priority, placing it alongside traditional pharmacovigilance data sources like EudraVigilance and spontaneous adverse event reports.
The EMA’s framing treats AI search outputs as a potential source of drug safety signals — not just a communication risk. If large numbers of patients are asking AI systems about a particular side effect, that query pattern itself may indicate an emerging adverse event signal that warrants regulatory attention. Whether drug companies are positioned to detect and report such signals is a question their pharmacovigilance teams need to answer.
Tracking AI Share-of-Voice: What Pharma Brand Teams Are Missing
How Often Does ChatGPT Mention Ozempic vs. Wegovy vs. Mounjaro?
Share of voice — the proportion of relevant conversations or impressions a brand captures relative to competitors — is a core metric in pharmaceutical brand management. Traditional share-of-voice measurement covers TV and print advertising, search engine visibility, physician detailing frequency, and social media mentions.
AI-generated responses are not yet part of most pharmaceutical brand tracking programs. They should be.
When patients and caregivers ask AI systems about GLP-1 drugs for weight loss, the responses do not distribute brand mentions evenly. Based on structured query testing across ChatGPT, Gemini, and Perplexity conducted by multiple health tech researchers, Ozempic consistently receives more unprompted mentions than Wegovy in conversational queries about weight loss — even though Wegovy is the FDA-approved indication for obesity management and Ozempic is approved only for type 2 diabetes. The AI is reflecting the cultural salience of the Ozempic brand name, which dominated media coverage and social conversation in 2022 and 2023, rather than making clinically appropriate brand distinctions.
For Novo Nordisk, this is a double-edged problem. Ozempic’s AI share-of-voice dominance means the company’s brand is highly visible in AI-mediated weight loss conversations — but that visibility is generating off-label associations that the company neither sought nor can easily correct.
Do LLMs Recommend Generic Drugs More Often Than Branded Alternatives?
Generic substitution is a consistent pattern in LLM drug recommendations. When asked to compare a branded drug to its generic equivalent, AI systems — likely reflecting the cost-focused content that dominates patient forums and consumer health writing — tend to recommend the generic. This is often clinically appropriate. For some drug classes and some patients, it is not.
The pattern becomes commercially significant for branded drugs with active patent protection or where formulation differences are clinically meaningful. Extended-release formulations, drug-device combinations, and drugs with narrow therapeutic index characteristics can present real clinical differences between branded and generic versions. AI systems, drawing on consumer-facing web content, frequently flatten those distinctions.
For brand teams managing drugs with meaningful formulation advantages, the AI share-of-voice picture is often bleak. The generic name dominates LLM responses not because the AI has evaluated clinical evidence, but because generics dominate the cost-focused content that fills patient forums, insurance company blogs, and pharmacy benefit manager communications.
How Eli Lilly Monitors AI Mentions of Mounjaro and Zepbound
Eli Lilly has not made detailed public disclosures about its AI monitoring program, but the company’s investor communications and regulatory filings through 2024 indicate active investment in digital intelligence infrastructure. Lilly’s medical affairs team has referenced social listening and digital signal monitoring as components of its post-approval surveillance approach for tirzepatide.
Industry sources suggest that Lilly, like Novo Nordisk, is working with third-party digital intelligence vendors to track AI-generated mentions of its GLP-1 assets — a practice that was nonexistent two years ago and is now becoming standard at companies with high-profile brands in crowded therapeutic categories.
Tools like DrugChatter are designed specifically for this purpose: querying multiple LLMs and AI search engines with structured pharmaceutical prompts, capturing and categorizing the responses, and identifying patterns in how specific drugs are described, compared, and recommended across AI systems. For brand teams trying to understand their AI share-of-voice without building proprietary query infrastructure, these tools provide a practical starting point.
How Novo Nordisk Tracks Semaglutide Mentions Across AI Platforms
The Ozempic/Wegovy situation has made semaglutide one of the most closely monitored drug brands in AI search. Novo Nordisk’s communications and public affairs teams have been actively engaged with the broader social media discourse around semaglutide since 2022, and that engagement has extended into AI-mediated channels.
The company faces a specific challenge: its most prominent brand, Ozempic, has become a cultural shorthand for GLP-1 weight loss drugs in the way “Kleenex” became a shorthand for facial tissue. When AI systems use “Ozempic” generically to describe the entire GLP-1 drug class, Novo Nordisk’s brand is being used in ways that conflate its diabetes indication with obesity medicine and sweep competitor products into its brand identity.
Monitoring and quantifying this pattern across AI outputs is a prerequisite for any brand protection strategy. Without systematic AI query tracking, the extent of the problem is invisible.
Patient Sentiment in LLMs: What Pharma Can Learn From AI-Mediated Conversations
How Patients Ask About Drug Interactions in AI Search
Patient behavior in AI search differs from traditional search behavior in ways that matter for pharmaceutical intelligence. In traditional Google search, patients typically search for symptoms, conditions, or specific drug names. In AI search, they ask questions in natural language — and those questions reveal more about their actual concerns, fears, and knowledge gaps.
Query analysis from AI health platforms consistently shows that patients ask drug interaction questions using social or personal framing: “my doctor put me on both Eliquis and ibuprofen, is that safe?” or “can I take melatonin while on Lexapro?” The conversational framing reveals the specific drug combinations, the clinical context, and often the prescribing relationship — information that traditional search query data does not capture.
For pharmaceutical companies with pharmacovigilance obligations, this query pattern represents a potential signal source. A spike in AI queries about a specific drug combination or side effect may indicate a real-world prescribing pattern or patient concern that warrants investigation. Companies that are not monitoring AI query patterns are not monitoring a channel where patients are actively communicating their drug experiences and concerns.
What Physician Queries in AI Reveal About Prescribing Behavior
Physicians use AI tools. A 2024 survey by the American Medical Association found that 38% of physicians reported using AI search tools for clinical information at least occasionally, up from 12% in 2022. A subset use AI as a first-pass reference for drug dosing, interaction checking, and off-label use evidence.
The query patterns physicians use in AI search differ from patient queries and from what they ask their drug information liaisons. In AI, physicians often ask the questions they would be embarrassed to ask a sales representative: “what’s the real evidence for X drug vs. Y drug in treatment-resistant cases?” or “is there any data on using this off-label for this indication?”
The AI answers to these questions shape prescribing behavior in ways that are entirely outside the traditional medical affairs monitoring framework. A physician who receives a misleading or incomplete AI answer about a drug’s evidence base may make different prescribing decisions than one who has been properly educated through medical affairs channels. Pharma companies that are not monitoring what AI tells physicians about their drugs are operating blind in a channel that is directly influencing prescribers.
Identifying Emerging Patient Concerns Before They Trend
One of the most actionable applications of AI output monitoring is early identification of patient concerns before they reach social media trend status or regulatory visibility. Reddit and other patient forums often surface emerging drug concerns weeks or months before they appear in adverse event reports or press coverage.
Because LLMs are trained on and often retrieve from these forums, they can function as an early warning system — if pharmaceutical companies are systematically querying AI systems about their drugs and tracking shifts in the concerns those systems surface.
The hair loss concern associated with GLP-1 drugs is an illustrative case. Reports of telogen effluvium — stress-related hair loss associated with rapid weight loss — began circulating in GLP-1 patient communities in 2022. The concern spread through Reddit, then to patient advocacy sites, then to mainstream health media. AI systems trained on this corpus began surfacing hair loss as a GLP-1 concern in late 2023. By 2024, the FDA had added language to GLP-1 drug labels and the issue was widely covered in medical media.
A pharmaceutical company monitoring AI outputs systematically in 2022 would have seen this concern emerging in AI-mediated patient conversations well before it reached regulatory or media prominence. That early signal has real value for medical affairs teams, safety teams, and brand communications functions.
AI Hallucinations and Drug Safety: The Pharmacovigilance Problem
Can AI Hallucinations Trigger FDA Adverse Event Reporting Obligations?
AI hallucinations in drug information take several forms. The most dangerous are confident, specific, and wrong — claims about contraindications that don’t exist, drug interactions that have no clinical basis, or side effects attributed to the wrong drug. Less dangerous but more common are synthesis errors: accurate facts combined in misleading ways, or accurate information about one drug applied to a different drug in the same class.
The question of whether a pharmaceutical manufacturer has a pharmacovigilance obligation when an AI system hallucinates adverse event information about their drug is genuinely unsettled. The FDA’s existing adverse event reporting regulations under 21 CFR 314.81 require manufacturers to report information about adverse drug experiences that they “receive.” The question is whether AI-generated content about a drug constitutes information “received” by the manufacturer, and whether it constitutes an adverse drug experience report.
Most regulatory attorneys who have analyzed this question conclude that a pure hallucination — fabricated adverse event information with no patient report underlying it — does not constitute a reportable adverse event. But the situation becomes murkier when AI systems are synthesizing and amplifying real patient reports from forums that manufacturers are already monitoring. In those cases, the AI output is a vector for information that may carry reporting obligations, and companies need clear SOPs for how to handle it.
Real Cases: When AI Drug Information Caused Actual Patient Harm
Documented cases of AI-mediated drug harm are beginning to accumulate in the medical literature and press. In 2023, a case report in JAMA described a patient who had altered their medication regimen based on AI-generated advice that contradicted their physician’s instructions. The patient cited the AI’s confident, specific language as the reason they trusted it over their doctor.
In the UK, the National Health Service digital safety unit has documented multiple cases where patients presented to emergency departments citing AI-generated medication guidance as the basis for decisions that led to hospitalizations. The drugs involved included anticoagulants, insulin, and antidepressants — all drugs where adherence to prescribed protocols is clinically critical and where community forum guidance is particularly unreliable.
These cases are not yet numerous enough to constitute an epidemiological signal, but they establish a pattern. As AI health search becomes more common and as patients increasingly treat AI outputs as authoritative, the frequency of AI-mediated medication errors will increase. Pharmaceutical companies that have not positioned their pharmacovigilance systems to monitor AI outputs will be late in detecting their drugs’ involvement in these events.
Off-Label Use Discussions in AI: What Monitoring Reveals
Off-label drug use is legal, common, and clinically important. It is also a promotional minefield for pharmaceutical manufacturers, who are prohibited from marketing drugs for unapproved indications. AI systems have no such constraints.
LLMs readily discuss off-label uses of branded drugs, drawing on the extensive clinical literature, case reports, and forum discussions that document off-label applications. For drugs with widely recognized off-label uses — gabapentin for anxiety, metformin for PCOS and longevity, low-dose naltrexone for fibromyalgia — AI systems provide detailed, often accurate information about off-label applications to anyone who asks.
This creates a specific competitive intelligence problem. A pharma company may be aware that its drug is used off-label for a particular condition, but if it is not monitoring what AI systems say about that off-label use, it may be missing important signals about how that use is spreading, what safety concerns are surfacing in connection with it, and how competitor drugs are being positioned in the same off-label space.
Tools like DrugChatter track off-label discussion patterns across LLMs as part of a broader AI monitoring capability — providing pharmaceutical companies with visibility into AI-mediated off-label discourse that would otherwise be invisible to traditional pharmacovigilance and brand monitoring systems.
AI Search Share-of-Voice: The New Competitive Battlefield
Tracking Share-of-Voice Across ChatGPT, Gemini, and Claude
Share-of-voice in AI search is not simply the frequency with which a drug is mentioned. It encompasses the context of the mention (positive, negative, neutral), the clinical framing (first-line vs. second-line, preferred vs. alternative), the comparative positioning against competitors, and the source attribution (whether citations point to regulatory documents, clinical literature, or consumer forums).
Different AI systems produce meaningfully different drug share-of-voice profiles. ChatGPT tends to be more conservative and hedging in drug recommendations, frequently directing users to consult physicians. Gemini’s drug responses are more likely to incorporate Google Health information and structured medical content. Perplexity sources from live web content and shows more variance — its drug information quality depends heavily on which web sources are currently ranking for related queries.
Claude, Anthropic’s AI system, tends to be more explicit about uncertainty and more likely to reference prescribing information directly — though like all LLMs, it is not immune to reflecting the biases of its training corpus.
For pharmaceutical brand teams, this means that share-of-voice monitoring needs to be platform-specific. A brand that is well-positioned in ChatGPT responses may be poorly positioned in Perplexity, where live web sourcing from forums changes the competitive landscape dynamically.
Which Drugs Are Most Frequently Mentioned by AI Systems?
Based on structured query testing and published research, the drugs that receive the highest volume of AI-mediated discussion are predictably the ones with the highest consumer visibility: GLP-1 agonists (semaglutide, tirzepatide), ADHD medications (Adderall, Vyvanse, Concerta), antidepressants (SSRIs as a class, with Lexapro and Prozac most frequently named), statins (atorvastatin, rosuvastatin), and anticoagulants (Eliquis, Xarelto, warfarin).
These are also the drug categories with the most active patient communities on Reddit and other forums — which is not a coincidence. LLM training and retrieval weighting reflects the volume and engagement of the underlying content, and patient forum content in these categories is extraordinarily high-volume.
Drugs with lower consumer visibility but high clinical importance — many oncology drugs, rare disease treatments, specialty biologics — receive less AI-mediated discussion volume, but the discussion that does occur is often of lower quality, drawing from smaller and less medically reviewed content pools.
Branded vs. Generic Drug Positioning in AI Responses
The pattern in LLM drug responses consistently favors generic names over brand names in clinical discussions. This reflects both training data patterns (clinical and scientific literature uses generic names) and a likely training signal from cost-focused consumer content that frames generics as the rational patient choice.
The practical consequence for brand teams is significant: AI systems tend to recommend “atorvastatin” rather than “Lipitor,” “escitalopram” rather than “Lexapro,” and “apixaban” rather than “Eliquis.” When a patient asks an AI “what’s a good medication for cholesterol,” the AI is far more likely to name a generic than a branded alternative — not because it has evaluated relative clinical merit, but because the training and retrieval signals favor generic nomenclature.
For companies managing drugs still under patent with branded pricing strategies, this is a measurable share-of-voice problem that existing brand tracking programs are not capturing.
Building a Pharmaceutical AI Monitoring Program
What a Pharma AI Query Monitoring Program Looks Like in Practice
An effective pharmaceutical AI monitoring program has four components: structured query design, multi-platform coverage, response categorization, and integration with downstream functions (pharmacovigilance, brand, medical affairs, regulatory).
Structured query design means developing a systematic set of queries that cover the full range of questions patients, caregivers, and physicians might ask about a drug. This includes indication queries, dosing queries, side effect queries, drug interaction queries, comparative effectiveness queries, and cost/access queries. It means querying in natural patient language, not clinical language — because that is how patients actually query AI systems.
Multi-platform coverage means running queries across at least ChatGPT, Gemini, Perplexity, and Claude, because the outputs differ meaningfully across platforms. A monitoring program that covers only one AI platform is missing the majority of AI-mediated drug conversations.
Response categorization means systematically tagging and coding AI outputs by clinical accuracy, source attribution, brand mention context, competitive positioning, safety language presence, and off-label content — a process that requires either manual review by medically trained personnel or automated classification tools specifically designed for pharmaceutical AI monitoring.
How to Detect AI Hallucinations About Your Drug
Detecting hallucinations in AI drug outputs requires a reference layer: an accurate, up-to-date representation of what the drug’s prescribing information, clinical evidence base, and approved label actually says. Every AI output is compared against this reference to identify discrepancies.
The most common hallucination patterns in pharmaceutical AI outputs are: incorrect contraindications (the AI cites a contraindication that doesn’t exist in the label), missed contraindications (the AI omits a contraindication that does exist), incorrect dosing information (wrong doses, wrong intervals, wrong titration schedules), false drug interactions (citing interactions not supported by clinical evidence or the label), and misattributed adverse events (assigning adverse events from one drug in a class to a different drug).
Systematic detection requires querying AI systems with specific, targeted prompts designed to elicit each of these response types, then comparing outputs against the reference. This is not a one-time task; it needs to run on a recurring schedule because AI systems update, retrain, and change their web retrieval sources in ways that can shift output quality without notice.
Integrating AI Monitoring With Existing Pharmacovigilance Systems
The integration question is where most pharmaceutical AI monitoring programs currently stall. Pharmacovigilance departments operate on regulatory timelines, with defined data flows, validated systems, and documented SOPs. AI monitoring outputs do not yet fit neatly into these structures.
The practical approach most companies are taking is a phased integration: AI monitoring outputs are initially managed as a signal enrichment layer alongside — but separate from — traditional pharmacovigilance data. Signals that meet defined criteria (e.g., AI outputs describing adverse events not in the current label, drawing on forum discussions with multiple confirmatory reports) are escalated for review by safety personnel using existing SOP frameworks.
This approach is pragmatic but imperfect. It treats AI monitoring as an additive function rather than a core pharmacovigilance data stream. As regulatory guidance matures and as AI monitoring methodologies become more standardized, the integration will need to deepen.
What Pharma Brand Teams Can Learn From Reddit AI Citations
Reddit’s role as an AI citation source is not purely a problem to be managed — it is also a signal source to be mined. The patient language that dominates Reddit discussions about a drug is the same language patients use when querying AI systems, and it is the language those AI systems reproduce in their outputs.
Understanding how patients talk about a drug on Reddit — the specific symptoms they describe, the comparisons they draw, the fears they express, the workarounds they devise — gives pharmaceutical brand and medical affairs teams insight into the patient experience that is often richer than what formal patient-reported outcome surveys capture.
When AI systems synthesize and reflect this language back in their outputs, they are effectively creating a feedback loop: patient forum language shapes AI training, AI outputs reinforce that language among new patients, and the cycle repeats. Brand teams that understand what language is embedded in this cycle can design communications that either align with patient vocabulary (making medical information more accessible) or correct dangerous framings before they become entrenched in AI outputs.
The Competitive Intelligence Opportunity in AI Drug Monitoring
Tracking Competitor Drugs in AI Responses
Competitive intelligence in AI search goes beyond tracking your own drug’s share-of-voice. The more strategically valuable question is: how does AI position your drug relative to competitors in head-to-head queries?
Queries like “Eliquis vs. Xarelto: which is better?” or “Ozempic vs. Mounjaro for weight loss” are among the most common pharmaceutical queries in AI search. The answers these systems produce draw on the comparative clinical literature, patient forum preference data, formulary guidance content, and pharmacoeconomic analyses that are freely available on the web — and they are producing comparative conclusions that influence both patient preference and, increasingly, prescriber information-seeking behavior.
Understanding how AI systems characterize your drug in comparative contexts — what clinical advantages they cite, what limitations they acknowledge, which competitors they favor — gives brand and medical affairs teams actionable intelligence for addressing gaps in the evidence-based narrative that is shaping AI outputs.
Monitoring AI Mentions During Drug Patent Expiry
Patent expiry represents one of the highest-stakes periods for pharmaceutical AI monitoring. In the months before and after a drug loses exclusivity, AI systems reflect the rapid proliferation of generic discussions, cost comparison content, and substitution guidance that floods the web. This is precisely when accurate, label-consistent information is most commercially important — and when AI outputs are most likely to accelerate generic substitution.
The monitoring imperative during patent cliff periods is to understand what AI systems are telling patients and physicians about generic availability, bioequivalence, and formulation differences — and to ensure that any clinically meaningful distinctions between the branded drug and generic versions are accurately reflected in the content that AI systems retrieve.
DrugPatentWatch, which tracks pharmaceutical patent status and generic entry timelines, is a useful reference for identifying which drugs are approaching patent expiry and prioritizing AI monitoring resources accordingly. Integrating DrugPatentWatch data with AI monitoring outputs creates a competitive intelligence layer that is particularly valuable for brand teams managing the transition from exclusive to multi-source markets.
How AI Citation Sources Reveal Physician Information-Seeking Patterns
When Perplexity or ChatGPT with browsing cites a specific clinical paper, treatment guideline, or formulary document in its drug responses, it is revealing something about the information architecture that is shaping AI-mediated drug discussions. The cited sources are the pages that search and retrieval algorithms are ranking most highly for relevant queries — and those rankings reflect real-world information-seeking patterns.
For pharmaceutical medical affairs teams, tracking which clinical papers, guidelines, and formulary documents AI systems are citing for queries about their drugs tells them which evidence is currently most influential in the AI-mediated information environment. That is not simply an academic observation — it is a guide to where medical affairs investment in evidence generation and publication strategy can have the most impact on AI output quality.
Regulatory and Legal Exposure From AI-Generated Drug Content
Drug Company Liability When AI Spreads Misinformation About Their Products
The liability question is live and unresolved. There is no definitive legal precedent yet establishing that a pharmaceutical manufacturer bears liability for AI-generated misinformation about its products. There is, however, a growing body of legal analysis suggesting that manufacturers who are aware of systematic AI misinformation about their drugs — and who take no steps to correct it — may face exposure under product liability theories or under FDA’s misbranding provisions if the AI content is sufficiently linked to company-controlled channels.
The risk is clearest in two scenarios. First, where a manufacturer operates or controls an AI-powered patient support tool that generates inaccurate drug information. Second, where a manufacturer’s own digital marketing content — optimized to rank highly in search and thus to be retrieved by AI systems — contains claims that are incomplete or misleading when stripped of their original regulatory-compliant context and synthesized into AI outputs.
Legal departments at major pharmaceutical companies are actively analyzing both scenarios. The consensus view, based on public statements and industry conference presentations, is that regulatory-compliant content hygiene — ensuring that content the company controls and publishes is accurate, complete, and appropriately caveated — is the most defensible risk management posture.
FDA Enforcement Precedents That Apply to AI Drug Content
The FDA has an established enforcement record on digital drug promotion that pharmaceutical companies should apply to AI contexts. Key precedents include:
The 2014 warning letters to companies using sponsored search results (paid search ads) that linked to pages lacking fair balance of risk information.
The 2010 guidance on responding to unsolicited requests for off-label information in social media, which established principles for managing drug information in channels the company does not fully control.
Multiple warning letters to companies whose digital marketing content — including websites and social media posts — presented efficacy claims without adequate risk disclosure.
None of these precedents directly addresses AI-generated content, but they collectively establish the FDA’s interpretive framework: the relevant question is whether drug information reaching consumers is accurate, complete, and appropriately contextualized — not whether it was generated by a human or an AI system. Companies that apply this standard to their AI monitoring and response programs will be better positioned than those waiting for AI-specific FDA guidance before acting.
Social Media Drug Misinformation Litigation: What AI Amplifies
Several pharmaceutical companies have engaged in litigation or regulatory disputes involving social media drug misinformation — cases where patient forum content, influencer posts, or viral health content made unsupported claims about drugs that the companies argued created commercial harm or pharmacovigilance obligations.
AI systems that train on and retrieve from social media content effectively amplify the reach of that content into an authoritative-sounding synthesis. The misinformation that circulated in a Reddit thread with 500 upvotes may, through AI retrieval and synthesis, reach millions of users who would never have encountered the original thread.
For pharmaceutical companies that have already identified specific social media misinformation patterns about their drugs, monitoring whether those patterns are being amplified in AI outputs is an immediate priority. The legal and regulatory exposure from AI-amplified misinformation is meaningfully greater than from the original social media content, because the AI output context strips away the social cues — the downvotes, the contradicting replies, the “this is not medical advice” disclaimers — that partially contextualize forum content as informal peer discussion.
The Path Forward: Pharmaceutical AI Monitoring as Standard Practice
Why AI Monitoring Will Become a Pharmacovigilance Requirement
The trajectory of FDA and EMA regulatory guidance is toward more inclusive definitions of the information environments pharmaceutical manufacturers are expected to monitor. The agencies have consistently moved in this direction as new digital channels have emerged — from the internet in the late 1990s, to social media in the 2010s, to AI-mediated content now.
The specific AI monitoring requirements that regulators will eventually codify are not yet defined. But the general direction is predictable: manufacturers will be expected to have systematic processes for identifying when AI systems are generating materially inaccurate information about their drugs, and for reporting adverse event signals that emerge from AI-mediated patient discussions.
Companies that build AI monitoring capability now — before it is required — will have a compliance advantage, a pharmacovigilance advantage, and a brand intelligence advantage over those who wait for regulatory mandates.
Building an Internal AI Query Testing Protocol
Pharmaceutical companies can begin building AI monitoring capability with a relatively modest initial investment. A structured protocol for testing AI outputs involves three elements:
A standardized query library covering the full range of questions patients, caregivers, and physicians ask about the drug — organized by indication, dosing, safety, interactions, comparatives, and cost/access. This library should be built in collaboration with medical affairs, pharmacovigilance, and brand teams to ensure coverage of the highest-risk query types.
A reference document set against which AI outputs are evaluated — the current prescribing information, current clinical trial data, current guidelines, and any FDA-approved labeling updates. This reference set needs to be maintained as living documents, updated whenever the label or clinical evidence changes.
A scoring and classification framework for AI outputs that captures clinical accuracy, brand mention context, competitive positioning, source attribution, and the presence or absence of required safety language. Outputs that fall below accuracy thresholds in high-risk categories (dosing, contraindications, interactions) trigger escalation protocols.
Platforms like DrugChatter provide an alternative to building this infrastructure from scratch — offering purpose-built pharmaceutical AI query and monitoring capabilities across multiple LLM platforms. For companies that cannot justify the internal development investment for an initial AI monitoring program, third-party tools provide a faster path to visibility.
Aligning AI Monitoring Across Medical Affairs, Brand, and Regulatory
The organizational challenge of pharmaceutical AI monitoring is as real as the technical challenge. AI outputs about a drug have relevance to at least four functions: pharmacovigilance (adverse event signals), brand management (share-of-voice and positioning), medical affairs (physician information quality), and regulatory affairs (compliance with labeling and promotional regulations).
In most pharmaceutical organizations, these functions do not share a common data infrastructure or reporting cadence. A pharmacovigilance team focused on ICSRs does not routinely share intelligence with a brand team focused on digital share-of-voice. A medical affairs team publishing health economic outcomes research does not routinely coordinate with a regulatory affairs team reviewing AI-generated promotional content.
Effective AI monitoring requires creating a shared intelligence function that aggregates AI output data and distributes relevant signals to each function according to their specific use cases. This is less a technology problem than an organizational design problem — one that companies are beginning to address through cross-functional AI governance committees and centralized digital intelligence teams.
Key Takeaways
AI systems including ChatGPT, Gemini, and Perplexity regularly source drug information from Reddit, patient forums, and consumer health blogs rather than FDA labels or prescribing information — producing outputs that can be clinically misleading or factually wrong.
GLP-1 drugs, ADHD medications, anticoagulants, and antidepressants generate the highest volume of AI-mediated drug discussion, with patient forum content dominating the training and retrieval signals that shape AI outputs.
AI share-of-voice is a real and unmeasured brand metric. LLMs consistently favor generic names over branded alternatives, amplify off-label use discussions, and produce comparative drug recommendations that do not always align with clinical evidence.
Pharmacovigilance obligations in AI contexts are legally unsettled but directionally clear: companies that are not monitoring AI outputs about their drugs are operating with a systematic surveillance gap that regulators will eventually address.
Early signal detection is a concrete benefit of AI monitoring. Emerging patient concerns about drug side effects surface in AI-mediated discussions weeks or months before they reach traditional pharmacovigilance channels or mainstream media.
AI hallucination detection requires a structured, recurring query protocol tested against an up-to-date reference document set — a capability that most pharmaceutical companies do not yet have.
The organizational imperative is cross-functional: effective AI drug monitoring requires coordinated input and output sharing across pharmacovigilance, brand, medical affairs, and regulatory functions.
Tools purpose-built for pharmaceutical AI monitoring — including DrugChatter — provide a practical entry point for companies that cannot justify building proprietary AI monitoring infrastructure from scratch.
FAQ
What happens when an AI like ChatGPT gives wrong drug information sourced from Reddit?
The immediate risk is patient harm: a person acts on inaccurate dosing, interaction, or safety information. The regulatory and commercial risks are more diffuse but also real. If a manufacturer becomes aware that AI systems are generating materially inaccurate information about their drug — particularly information that could constitute a safety signal or that could be construed as off-label promotion — they face questions about pharmacovigilance reporting obligations and FDA compliance. The legal framework has not fully resolved these questions, but waiting for it to do so before acting is not a defensible risk management position.
Are pharmaceutical companies legally required to monitor what AI says about their drugs?
Not yet — there is no specific regulatory requirement as of mid-2025 mandating pharmaceutical AI monitoring. The FDA’s existing adverse event reporting regulations and promotional regulations apply to information manufacturers “receive” and to promotional content in channels they control. As AI becomes a more prominent health information channel, the agency’s interpretation of both frameworks is likely to expand. Companies that build monitoring capability ahead of regulatory mandates will be better positioned for compliance and for signal detection.
How do AI systems decide which drugs to recommend when a patient asks a general question?
LLMs do not “decide” in the clinical sense — they generate statistically likely responses based on training data patterns and, for retrieval-augmented systems, based on which web pages rank most highly for related queries. Drug recommendations emerge from the intersection of training corpus weighting and retrieval ranking signals. Consumer health content, patient forums, and high-traffic health websites dominate these signals for most drug queries. The result is that AI drug recommendations reflect the patterns in consumer health media rather than formal clinical decision frameworks.
What is the difference between AI share-of-voice and traditional pharmaceutical share-of-voice?
Traditional share-of-voice measures the proportion of advertising spend, sales force calls, or media mentions a brand captures relative to competitors. AI share-of-voice measures how often and in what context a drug appears in AI-generated responses to relevant queries — including unprompted mentions, comparative positioning, and the sentiment and clinical framing of each mention. AI share-of-voice is not yet captured by traditional brand tracking programs, and it can differ significantly from traditional share-of-voice metrics. A brand with minimal advertising may nonetheless dominate AI responses if its name is culturally prominent or if its patient community generates high-volume forum content.
Can pharmaceutical companies improve how AI systems describe their drugs?
Indirectly, yes. AI systems are influenced by the quality, volume, and retrievability of the content available on the web. Pharmaceutical companies can improve their AI visibility by publishing clear, accessible, patient-readable content about their drugs on authoritative domains, ensuring that prescribing information and patient guides are crawlable and properly structured for web retrieval, and creating clinical content that is semantically rich enough to rank for the query types patients and physicians actually use in AI search. Direct manipulation of LLM training is not possible for external parties, but the web content that shapes retrieval-augmented AI outputs is absolutely something manufacturers can influence through content strategy.