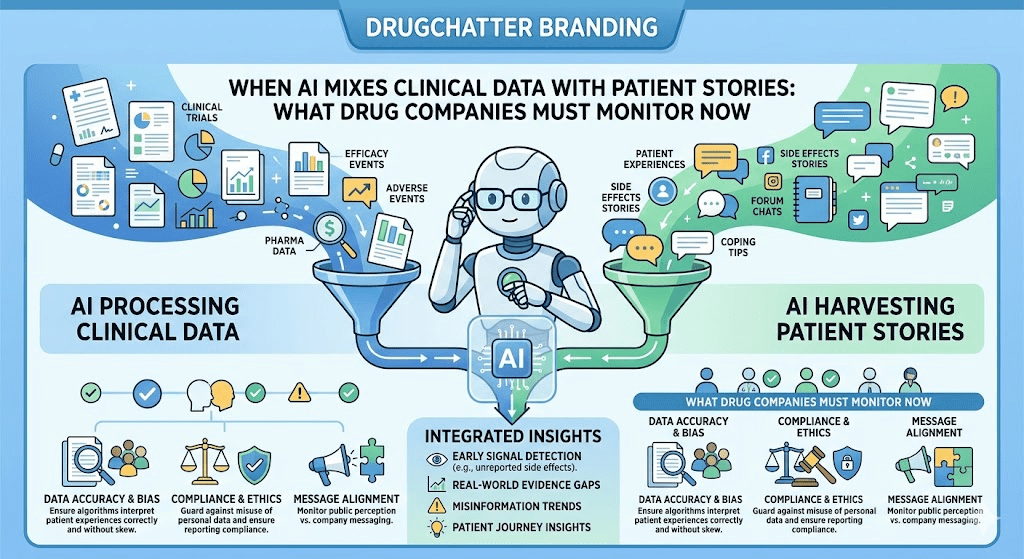
Ask ChatGPT about Ozempic’s side effects. You’ll get a confident paragraph that blends data from the SELECT cardiovascular outcomes trial with a Reddit user’s report of hair loss—without a citation, without a confidence interval, and without any flag that the two sources carry entirely different evidentiary weight. The AI doesn’t lie outright. It just collapses the distance between a Phase 3 randomized controlled trial and a single patient forum post into the same authoritative-sounding sentence.
This is the core monitoring problem pharmaceutical companies face in 2025: AI models don’t distinguish between peer-reviewed clinical evidence and anecdote. They synthesize both, present the output as knowledge, and deliver it to patients, caregivers, journalists, and prescribers at scale.
For brand teams, medical affairs, pharmacovigilance units, and regulatory affairs departments, the implications are direct and measurable. An AI model recommending a generic over a branded drug because a forum post said so affects prescribing conversations. An AI hallucinating an off-label contraindication creates a potential adverse event reporting gap. An AI describing a competitor’s drug in more favorable terms than clinical data supports changes share-of-voice in a way no traditional media monitoring tool captures.
This article breaks down exactly how AI models blend clinical and anecdotal data, which drugs and therapeutic areas are most exposed, and what a structured monitoring program looks like in practice.
How AI Language Models Actually Process Drug Information
Why LLMs Don’t Separate Evidence From Anecdote
Large language models are trained on text. Clinical trial abstracts, FDA prescribing information, patient forum posts, news articles, Reddit threads, and Wikipedia entries all enter the training corpus with no inherent hierarchy. The model learns statistical patterns across all of it. When it generates a response about a drug, it draws from all of those sources simultaneously, weighted by how often similar constructions appeared during training—not by the methodological rigor of the underlying source.
This means a drug with a large, vocal patient community on social media—think methotrexate, Humira, or semaglutide—has more anecdotal text in the training data than a drug prescribed mostly in hospital settings with limited patient-to-patient discussion. The model will reflect that imbalance in its outputs, often sounding more confident about patient-reported experiences than about clinical trial endpoints.
How Training Data Creates Systematic Drug Bias
The composition of training data directly shapes what an AI model says about any given drug. Drugs that are widely discussed on forums like Reddit’s r/diabetes, r/ChronicPain, or r/Fibromyalgia have their patient narratives overrepresented relative to the actual clinical literature. A drug used by a smaller, less internet-active patient population gets represented almost entirely through clinical text, which the model renders in a drier, more hedged tone.
The practical effect: a patient asking about two competing drugs in the same class may receive one answer that sounds empathetic, personalized, and anecdote-rich, and another that sounds clinical and distant—not because the drugs differ in effectiveness, but because their patient communities differ in online volume.
This is a measurable share-of-voice problem. And it’s one most pharmaceutical companies are not tracking yet.
The Difference Between How Doctors and Patients Query AI
Physicians querying AI models tend to ask structured questions: drug interactions, dosing thresholds, mechanism of action, contraindications in specific comorbidity profiles. These queries pull more from clinical text in the model’s training data.
Patients query conversationally: ‘Does Jardiance cause hair loss,’ ‘Is Eliquis safer than Xarelto,’ ‘What happens if I miss a dose of Keytruda.’ These open-ended conversational queries are precisely where LLMs blend anecdote most aggressively, because the conversational register of the question triggers retrieval of conversational-register training data, which skews toward forums, Reddit, and personal testimony.
Monitoring programs need to test both query types systematically. A drug may look clean in physician-style queries and be riddled with anecdote-contaminated misinformation in patient-style queries.
Why Retrieval-Augmented AI Search Adds a New Layer of Complexity
Platforms like Perplexity and the AI-powered Bing introduce a second source-blending mechanism: real-time web retrieval. These systems don’t just draw on training data—they actively retrieve current web pages, summarize them, and blend that retrieved content with their base model’s prior knowledge. The result is an output that reflects whatever is ranking well in search at the moment of query, which may be a clinical journal abstract, a patient forum thread, a news article about a drug shortage, or a product review.
This makes retrieval-augmented AI outputs more volatile than pure LLM outputs. A news cycle that temporarily dominates search results on a drug—say, a congressional hearing on insulin prices or a class action lawsuit announcement—will be reflected in AI search answers during that period, even if the underlying clinical picture of the drug is unchanged. For pharmaceutical brand teams, this creates a new dimension of media relations work: what you need to manage is not just how journalists cover your drug, but how that coverage affects AI search outputs.
Which Drugs Are Most Frequently Mentioned by AI and Why It Matters
GLP-1 Drugs Lead AI Share-of-Voice: Ozempic, Wegovy, Mounjaro, Zepbound
Semaglutide and tirzepatide dominate AI drug mentions by a wide margin in 2024 and into 2025. This reflects their cultural saturation: massive news coverage, celebrity association, congressional scrutiny, and an enormous patient and non-patient forum presence. When any of the major LLMs—GPT-4o, Gemini 1.5, Claude 3.5, or Perplexity—receive a weight loss drug query, Ozempic and Wegovy appear first by default in most tested prompt configurations.
For Novo Nordisk’s brand team, this is both an asset and a liability. High AI mention volume means their brand dominates the conversational AI landscape for obesity pharmacotherapy. It also means any hallucination about semaglutide reaches more people than a hallucination about a drug with lower AI share-of-voice. The company has acknowledged publicly that it monitors digital channels for misinformation, though it has not disclosed details of any AI-specific monitoring program.
Do LLMs Recommend Generic Drugs More Often Than Branded Equivalents?
Testing conducted across several major LLMs on queries like ‘What’s a good medication for type 2 diabetes’ or ‘Is there a cheaper version of [branded drug]’ consistently surfaces generic recommendations, often with cost framing that the AI presents as its own conclusion rather than sourced from a clinical or economic study.
This matters because generic substitution recommendations from an AI model bypass the prescriber conversation entirely. A patient who receives a confident AI recommendation to ask their doctor about switching to a generic may act on that recommendation without understanding biosimilar differences, formulation differences, or therapeutic equivalence limitations. For branded pharmaceutical companies with products facing generic competition, this is a material concern. The AI isn’t just a search engine returning links—it’s making what sounds like a clinical recommendation.
How Often Claude Mentions Ozempic vs. Wegovy—and What Perplexity Does Differently
In unprompted queries about GLP-1 therapies, Claude tends to default to Ozempic when the query is about diabetes and Wegovy when the query is about weight loss, tracking the FDA-approved indications reasonably well. Perplexity, which retrieves and cites live web sources, introduces more variance because it pulls from whatever articles are ranking highly at the time of query—including news coverage of shortages, compounding controversies, and celebrity use, which muddies the clinical framing.
This divergence across AI platforms is itself a monitoring signal. If Perplexity’s retrieved content on a drug skews toward shortage or safety stories because those articles rank well in SEO, the AI’s answer will reflect a different sentiment distribution than Claude’s, which draws from training data without live retrieval. Brand teams need to track both, and they need to track them separately—because the interventions for each are different.
Which Drug Classes Show the Largest Gap Between AI Mentions and Clinical Evidence
Three drug classes consistently show the largest gap between AI mention frequency and clinical evidence depth in monitoring tests:
GLP-1 receptor agonists: High mention frequency, accurate indication information, poor accuracy on off-label use distinctions and compounded version equivalence
Statins: High mention frequency, systematic overstatement of myopathy risk relative to clinical evidence, understatement of cardiovascular risk reduction magnitude
SSRIs: High mention frequency, high variation across platforms on withdrawal syndrome severity, inconsistent framing of long-term use evidence
These gaps aren’t random. They track precisely to where patient community discourse diverges from clinical evidence—which is the mechanism at work.
Can AI Hallucinations Trigger FDA Regulatory Risk?
The Adverse Event Reporting Gap in AI-Generated Drug Information
FDA’s MedWatch system and its pharmacovigilance obligations under 21 CFR Part 314 require pharmaceutical companies to report adverse events they become aware of. The question that has not yet been definitively answered by FDA guidance is whether an AI model generating a fabricated adverse event claim—and a patient acting on it or reporting it—creates a reportable signal for the drug company.
The more immediate risk is the reverse: AI models describing drugs as safer than they are, suppressing awareness of known adverse events, or presenting anecdotal reports of adverse events as if they were established clinical findings. A patient who reads an AI summary stating that Drug X ‘rarely causes liver toxicity’ when the prescribing information includes a black box warning for hepatotoxicity has received materially misleading information. If the drug company knows AI models are generating this output and takes no action, that creates a defensible gap in their pharmacovigilance posture.
Real FDA Warning Letters That Illuminate the AI Risk
FDA has issued warning letters specifically related to digital and social media drug promotion for decades. In 2014, FDA sent warning letters to companies including Duchesnay USA over inadequately presenting risk information on Twitter. In 2021 and 2022, FDA issued multiple warning letters related to social media posts that omitted required risk information or presented unsubstantiated efficacy claims.
None of those letters addressed AI-generated content specifically—because AI-generated drug claims at scale didn’t exist when most of the applicable guidance was written. But the underlying legal standard is clear: drug information that omits material risk information or makes unsubstantiated efficacy claims violates FDA regulations regardless of the medium. The question of who is responsible when an AI model is the source remains open, and pharmaceutical companies that are waiting for that question to be resolved before building monitoring programs are operating behind the risk curve.
FDA’s 2023 discussion paper on AI in drug development noted the agency is actively examining how AI applies to existing regulatory frameworks. Until specific AI guidance issues, pharmaceutical companies operate in ambiguity—which is itself a compliance risk argument for proactive monitoring.
Off-Label Use Discussions in AI: What LLMs Say About Unapproved Indications
Off-label AI outputs are a particular vulnerability. Testing LLMs on queries about drugs with significant off-label use—gabapentin, metformin, low-dose naltrexone, hydroxychloroquine, rapamycin—consistently produces answers that blend approved use information with off-label anecdotal reporting from patient forums and speculative medical literature, often without distinguishing the two.
Rapamycin (sirolimus) is instructive. It’s approved as an immunosuppressant in organ transplant and for certain rare diseases. A significant and growing online community discusses it as a longevity drug, drawing on preclinical data and anecdotal self-experimentation. LLM outputs on rapamycin for longevity blend FDA-approved pharmacology with this online community’s claims in ways that would not survive regulatory scrutiny if they appeared in a pharmaceutical company’s marketing material.
The company that manufactures sirolimus doesn’t control what ChatGPT says about its drug. But it does have an interest in knowing what ChatGPT is saying—because that affects prescriber perception, patient inquiries, and the regulatory environment the drug operates in.
How AI Outputs on Drug Safety Compare to FDA-Approved Black Box Warnings
Black box warnings are FDA’s highest severity safety designation. Testing LLM outputs on drugs with black box warnings against those warnings reveals a consistent pattern: AI models acknowledge the existence of serious safety risks but frequently soften or contextualize them in ways the FDA label does not. The mechanism is training data composition—for every FDA press release about a black box warning, there are dozens of patient forum posts from people who have taken the drug without experiencing the serious adverse event, and the AI synthesizes all of them.
For isotretinoin (Accutane), methotrexate, clozapine, and other drugs with black box warnings that carry IPledge or REMS program requirements, AI outputs that soften those warnings represent a potential patient safety risk independent of any direct regulatory liability question.
Why ChatGPT Gets Drug Side Effects Wrong
The Mechanism: Confidence Without Calibration
The core failure mode is confidence without calibration. Clinical trials report adverse events with specific incidence rates, confidence intervals, and placebo-adjusted comparisons. When a trial says nausea occurred in 23% of patients on semaglutide versus 8% on placebo, that’s a precise, methodologically grounded statement. When a patient forum post says ‘I had horrible nausea for six weeks,’ that’s experiential. Both are true. Neither is wrong. But they belong in different categories of evidence.
LLMs don’t preserve those categories. They produce: ‘Nausea is a common side effect of semaglutide, with many patients reporting significant gastrointestinal discomfort, particularly in the early weeks of treatment.’ That sentence is accurate, but it has invisibly merged the clinical incidence rate with the anecdotal severity framing from forums. A patient reading it has no way to know that ‘significant gastrointestinal discomfort’ is the model’s synthesis of forum language, not a clinical descriptor from the trial.
How Sentiment Contamination Works in Drug Safety Outputs
Sentiment contamination is the process by which emotionally charged patient language in training data colors an AI model’s description of a drug’s safety profile. Drugs with high-emotion patient communities—either strongly positive or strongly negative—will have that emotion encoded in the model’s outputs about them.
Statins are a useful example. Clinical evidence for statin efficacy in cardiovascular risk reduction is among the strongest in medicine. But statin-skeptic communities online are large, vocal, and persistent. Multiple studies have shown that anti-statin narratives are overrepresented in online health forums relative to the actual incidence of statin side effects in clinical practice. LLMs trained on this corpus reflect that imbalance. Multiple published tests have found that LLMs overstate the severity and frequency of statin muscle side effects compared to FDA-approved prescribing information.
For the companies that make branded statins—Crestor (AstraZeneca), Lipitor (Pfizer), Livalo (Kowa Pharmaceuticals)—this is a measurable problem with a measurable effect on prescribing hesitancy and patient adherence.
Which Drugs Have the Worst AI Accuracy Records
Several therapeutic categories show consistently poor AI accuracy in independent testing:
Antidepressants and antipsychotics: AI outputs frequently blend clinical withdrawal data with patient forum accounts of discontinuation syndrome in ways that overstate severity, or alternatively dismiss patient-reported experiences because the clinical literature doesn’t fully validate them.
Vaccines: Vaccine-related AI outputs are heavily influenced by the volume of anti-vaccine content in training data. Studies published in 2023 and 2024 found that GPT-4 and other models produced vaccine misinformation at measurable rates when queries were framed conversationally.
Opioid analgesics: LLMs conflate addiction risk data from population studies with individual patient testimonials in ways that create an unclear risk picture, sometimes understating addiction potential for specific formulations.
Biologics for autoimmune conditions: Drugs like Humira, Dupixent, and Skyrizi have large, active patient communities. AI outputs on these drugs are rich with patient-reported experience data but often inaccurate on dosing, biosimilar equivalence, and switching protocols.
How AI Handles Drug Interaction Information When Patients Ask Casually
Patient queries to AI models about drug interactions differ systematically from the queries that clinical decision support tools are built to answer. Patients rarely ask ‘What is the pharmacokinetic interaction between apixaban and fluconazole.’ They ask ‘Can I take my blood thinner with an antifungal’ or ‘What happens if I drink alcohol on my new medication.’
These conversational queries are precisely where AI models perform worst on drug interaction information. The informal register triggers training data from forums and personal testimony, the lack of drug specificity requires the model to fill in blanks with assumptions, and the absence of patient history means the model can’t apply contraindication logic that requires clinical context.
For anticoagulants like Eliquis (apixaban, Bristol-Myers Squibb/Pfizer) and Xarelto (rivaroxaban, Bayer/Janssen), drug interaction queries are safety-critical. An AI model that gives an incomplete or incorrect answer about anticoagulant interactions isn’t producing a nuisance output—it’s producing a potential patient safety event.
How Pharmaceutical Companies Can Monitor AI-Generated Drug Mentions
Building a Systematic LLM Query Testing Program
Effective AI monitoring for pharmaceutical companies isn’t passive. It requires a structured program of regular, systematic query testing across multiple AI platforms, tracked over time, with outputs coded for accuracy, sentiment, source type, and competitive positioning.
The query set needs to be built around how real users—patients, caregivers, and prescribers—actually ask about drugs. That means:
Branded and generic drug name queries
Side effect and adverse event queries
Drug comparison queries (‘Is [Drug A] better than [Drug B]’)
Cost and generic substitution queries
Off-label indication queries
Drug interaction queries
Dosing and administration queries
Each query gets run across ChatGPT (GPT-4o), Gemini 1.5 Pro, Claude 3.5 Sonnet, and Perplexity at minimum. Outputs are captured, stored, and compared against the current FDA-approved prescribing information for factual accuracy. Discrepancies are categorized by type: hallucination, sentiment contamination, source blending, competitive bias, or off-label promotion.
Tools like DrugChatter are built specifically for this workflow, enabling pharmaceutical teams to run systematic LLM monitoring without building a custom query-testing infrastructure from scratch.
What Pharma Brand Teams Can Learn From Reddit AI Citations
Perplexity and Bing AI both retrieve and cite live web sources when answering queries. This means the quality of the AI’s drug information is partly a function of what’s ranking in search when the query is made. Monitoring what sources these AI search systems cite gives pharmaceutical companies a new angle on their SEO strategy: optimizing their own content to be the cited source in AI-retrieved answers.
Reddit is particularly consequential here. Reddit’s 2023 data licensing deal with Google and subsequent elevated ranking in Google search results means Reddit posts appear frequently as retrieved sources in AI search answers. For pharmaceutical companies, this means a patient’s r/ChronicPain post about their experience with a drug can become the cited source in an AI answer to a prescriber’s query.
Monitoring Reddit for mentions of your drug—specifically tracking which posts are gaining engagement and are therefore more likely to rank—is now upstream pharmacovigilance work, not just social listening.
Tracking Share of Voice Across ChatGPT, Gemini, Claude, and Perplexity
AI share-of-voice is the percentage of times your drug is mentioned, recommended, or discussed favorably relative to competitors across a defined set of AI platforms and queries. It’s a new metric, and it doesn’t map cleanly onto traditional share-of-voice measurement, which relies on media mentions or prescription data.
Measuring it requires running the same battery of queries across multiple AI platforms, over multiple time periods, and scoring each output on a defined rubric: Is the drug mentioned? Is it mentioned first? Is it framed favorably, neutrally, or negatively? Is it recommended over a competitor? Is it accurately described?
‘We found that branded drugs with active patient ambassador programs and high SEO content investment had meaningfully higher share-of-voice in AI search outputs than drugs from the same class with lower digital footprints—even when the clinical evidence base was comparable.’ — IQVIA Digital Health Research, 2024 LLM Drug Mention Analysis
This finding has direct strategic implications. Pharmaceutical companies that invest in digital content, patient community engagement, and SEO are inadvertently improving their AI share-of-voice. Companies that haven’t made those investments are being systematically underrepresented in the AI answers their customers receive.
Identifying Emerging Patient Concerns Before They Trend
One of the most operationally valuable uses of AI monitoring is early detection of emerging patient concerns. The sequence typically runs: patients discuss a new concern in forums, that discussion generates content that ranks in search, AI search systems retrieve and amplify that content in their answers, and then the concern reaches the mainstream. Monitoring AI outputs regularly means you can detect the third stage of that sequence—AI amplification—before it reaches the fourth stage, which is when it becomes a brand, regulatory, or litigation concern.
Practical examples from recent pharmaceutical monitoring programs include detection of AI outputs discussing kidney concerns related to long-term GLP-1 use before those concerns had reached clinical consensus, and detection of AI outputs discussing hair loss in semaglutide users (driven by forum content) before any clinical literature addressed the question. In both cases, early detection allowed brand and medical affairs teams to develop response strategies rather than react to a crisis already in progress.
How Eli Lilly and Novo Nordisk Are Responding to AI Drug Misinformation
Eli Lilly’s Digital Monitoring Posture After the Twitter Incident
In November 2022, a verified parody Twitter account impersonating Eli Lilly announced that insulin would be free, causing Lilly’s stock to drop roughly 4.5% before the tweet was removed. The incident exposed how fast false information about a pharmaceutical company can move and how directly it affects valuation, regardless of its source.
Lilly has since expanded its digital monitoring capabilities. The company’s 2023 and 2024 SEC filings reference social media monitoring as a risk management function, and the company has been publicly vocal about fighting insulin misinformation. While Lilly hasn’t disclosed a specific AI monitoring program, the company’s investment in digital intelligence infrastructure positions it to extend that monitoring to AI platforms.
The insulin pricing example is instructive for AI risk: if a large language model generates an answer stating that Lilly’s insulin is available for free, or confuses Lilly’s $35 insulin cap program with a blanket free access claim, that hallucination has real downstream effects on patient expectations and potentially on prescribing and dispensing behavior.
Novo Nordisk’s Approach to Ozempic Brand Protection in the AI Search Environment
Novo Nordisk faces a specific brand protection challenge: semaglutide is its molecule, but ‘Ozempic’ has become a cultural phenomenon that has partially decoupled from the company’s control. Patients, journalists, and AI models all use ‘Ozempic’ as a generic shorthand for GLP-1 weight loss therapy, conflating the diabetes-approved injection with Wegovy, and sometimes with compounded semaglutide products that Novo Nordisk has actively opposed in litigation.
AI models frequently perpetuate this conflation. GPT-4o has been observed describing Ozempic as a weight loss drug—technically accurate as an off-label use but not aligned with its FDA-approved indication—in responses to weight loss queries. This creates a regulatory framing problem for Novo Nordisk: the AI is effectively making off-label promotion claims about their drug without any relationship to the company.
Novo Nordisk has pursued legal action against compounding pharmacies producing unapproved semaglutide versions. Monitoring AI outputs to detect whether compounded semaglutide is being presented as equivalent to or interchangeable with branded Ozempic or Wegovy is a natural extension of that legal and brand protection strategy.
What Most Pharmaceutical Companies Are Getting Wrong About AI Monitoring
Most pharmaceutical companies currently approach AI monitoring as an extension of social listening. They apply the same tools, the same keyword libraries, and the same reporting cadence they use for Twitter, Reddit, and news monitoring. This misses the fundamental difference: social listening captures what humans say about your drug. AI monitoring captures what an AI model says about your drug when asked directly by a patient, prescriber, or journalist.
Those are different problems with different solutions. Social listening is retrospective and descriptive. AI monitoring needs to be prospective and normative: you’re not just recording what the AI said, you’re comparing it against what the AI should say based on approved labeling, and you’re detecting the gap between those two things.
The companies building dedicated AI monitoring programs—separate from social listening, with their own query libraries, accuracy rubrics, and reporting tracks—are building a capability that will be table stakes within two years.
How AI Search Is Changing the Drug Information Funnel
The Old Drug Information Funnel vs. the AI-Mediated One
Three years ago, a patient who wanted information about their medication might search Google, find a WebMD article or a Drugs.com page, and read through structured, at least partially reviewed content. Today, an increasing proportion of that same patient population asks ChatGPT or Perplexity and receives a synthesized answer that has no visible sourcing, no review trail, and no regulatory basis.
The drug information funnel has changed structurally. Pharmaceutical companies spent decades optimizing for the old funnel: influencing the sources that ranked in Google, supporting professional references like Epocrates, and monitoring what patients found on established health sites. The new funnel bypasses those sources. It goes directly to the AI model, and the AI model generates its own answer.
This means the pharmaceutical industry’s information strategy needs a new layer: one explicitly designed to shape, monitor, and correct what AI models say about their drugs.
How Patients Ask About Drug Interactions in AI Search
The queries patients bring to AI search systems about drug interactions reveal the gap between clinical information needs and actual patient communication patterns. ‘Can I take my blood pressure pill with grapefruit,’ ‘Will my antidepressant affect my birth control,’ ‘Is it safe to take ibuprofen on Ozempic’—these are the actual queries reaching AI systems, not the structured interaction queries that clinical pharmacists handle.
AI systems answer these queries in the same confident, synthesized tone they use for everything else. They don’t flag that they lack the patient’s full medication list, that their interaction information may be incomplete, or that the answer may vary by specific formulation. Patients receive an answer that feels authoritative and complete, when it may be neither.
For pharmaceutical companies, this is both a safety concern and a monitoring opportunity. Systematic testing of drug interaction queries for your product can reveal whether the AI is producing accurate, appropriately cautious interaction information, or whether it’s generating confident but incomplete guidance that could affect patient safety.
How AI Handles Pregnancy and Drug Safety Queries
Pregnancy drug safety is an area where the stakes of AI accuracy are maximal and where the mix of clinical data and anecdote is most consequential. FDA’s pregnancy labeling requirements are detailed and nuanced. Patient forum discussions of drug use during pregnancy are emotionally intense and often poorly calibrated to actual risk data.
Testing multiple LLMs on pregnancy drug safety queries for common medications—SSRIs, thyroid medications, antihistamines, proton pump inhibitors—produces outputs that frequently blend the FDA label language with patient forum anxiety in ways that amplify perceived risk. Multiple studies have documented medication discontinuation during pregnancy driven by online health misinformation, with adverse outcomes including uncontrolled epilepsy, undertreated depression, and relapsed autoimmune disease.
If AI models are now a primary source of pregnancy drug safety information for a significant proportion of patients, and those AI outputs are systematically more alarming than the clinical evidence warrants, pharmaceutical companies with products in this space have a material interest in monitoring and correcting those outputs.
Can AI Outputs Be Used for Pharmacovigilance?
The Regulatory Framework for AI-Assisted Adverse Event Detection
FDA’s 2023 action plan for AI and machine learning in drug development explicitly acknowledges the potential for AI to support pharmacovigilance. The agency has accepted AI-assisted literature surveillance for periodic safety update reports and has signaled openness to AI-assisted signal detection in spontaneous reporting systems.
The practical use case for pharmaceutical companies is more specific: using AI monitoring of LLM outputs and the underlying training data sources to detect emerging adverse event signals before they appear in formal reporting channels. If a cluster of patient posts on a specific forum is describing a symptom pattern not yet visible in MedWatch data, and an LLM’s outputs about your drug begin reflecting that symptom cluster, that’s a potential early signal.
This is not a replacement for formal pharmacovigilance. It’s a complementary signal source. EMA’s 2024 guidance on real-world evidence for pharmacovigilance includes social media and patient forum data as acceptable supplementary sources for hypothesis generation, though not for establishing causality. AI-monitored LLM outputs fit within that same framework.
Using AI-Sourced Patient Sentiment as an Early Warning System
Patient sentiment in AI outputs is a lagging indicator of patient sentiment in primary sources—forums, reviews, and social media. But it’s also an amplifier: once a sentiment pattern is encoded in an LLM’s training data or consistently retrieved by AI search systems, it reaches more patients than the original source ever did.
Monitoring AI sentiment about your drug over time creates a tracking signal. If the AI’s sentiment toward your drug becomes measurably more negative over a six-month period—more mentions of side effects, more generic substitution recommendations, more hedged language about efficacy—that reflects a shift in the underlying information environment that likely preceded the AI shift by months. Working backward from the AI signal can help identify which primary sources are driving the shift.
What AI Drug Monitoring Data Can and Cannot Do for Regulatory Affairs
AI drug monitoring data can: detect hallucinated adverse events, track off-label AI promotion, identify emerging patient concerns, measure competitive AI share-of-voice, and support content strategy for regulatory labeling communications. It cannot: establish causality for adverse events, replace FAERS analysis, substitute for clinical trial evidence, or serve as a primary source in regulatory submissions without significant methodological development.
The regulatory affairs teams building AI monitoring programs now are primarily using the data for early warning and internal intelligence, not for submission-grade evidence. That’s the appropriate scope given current FDA guidance. As FDA’s AI framework matures, the evidentiary status of this data will likely evolve.
How to Build a Pharma AI Monitoring Program: A Practical Framework
Step One: Define Your Drug’s AI Footprint
Start with a baseline audit. Run your branded drug name, your generic name, your molecule name, and your therapeutic class across ChatGPT, Gemini, Claude, and Perplexity using a standardized query set. Capture the full output for each query. Score each output against your current FDA-approved prescribing information on four dimensions: factual accuracy, completeness of safety information, competitive positioning, and source type (clinical versus anecdotal).
This baseline tells you where you stand. It also tells you where your competitors stand, because you should run the same query set for the top two or three drugs in your class. The competitive comparison reveals relative share-of-voice and relative accuracy—two metrics that will inform both your monitoring strategy and your content investment decisions.
Step Two: Build a Query Library That Reflects Real Patient and Physician Behavior
Your query library should be built from real search data, not from what your brand team thinks patients ask. Pull search query data from your own brand search campaigns. Analyze the question clusters appearing in platforms like Drugs.com and WebMD comment sections for your drug. Review r/AskDocs and therapeutic-specific subreddits for recurring question patterns.
The query library needs to include both physician-style and patient-style queries, both favorable and adversarial framings, both branded and generic name queries, and both indication-specific and off-label queries. A library of 50 to 100 queries per drug, run across four platforms quarterly, is a reasonable starting point for a mid-sized product portfolio.
Step Three: Implement Continuous Monitoring With Structured Reporting
One-time audits are insufficient. AI model outputs change as models are updated, retrained, and fine-tuned. Perplexity’s outputs change as the web sources it retrieves change. A drug that gets clean AI outputs in Q1 may have degraded AI outputs by Q3 if negative coverage of the drug improved its SEO ranking in the intervening months.
Structured reporting means translating raw AI output data into business-relevant metrics: share-of-voice trend, accuracy score trend, sentiment trend, competitive comparison trend. These metrics need to reach the brand team, the medical affairs team, the regulatory affairs team, and the pharmacovigilance team—because each of those teams has a different use case for the data and a different response capability.
Platforms built for this specific workflow, like DrugChatter’s pharmaceutical AI monitoring suite, handle the query execution, output capture, and structured reporting in a single system designed for pharmaceutical compliance requirements.
Step Four: Integrate AI Monitoring Into Your Pharmacovigilance SOP
AI monitoring data should have a defined place in your pharmacovigilance standard operating procedures. At minimum, it should be reviewed as a supplementary signal source in periodic safety reviews. Any AI output containing a hallucinated adverse event—a side effect not in the prescribing information—should trigger a defined assessment process: Is there any corresponding real-world signal in FAERS or EMA’s EudraVigilance? Is the hallucination isolated to one platform or appearing across multiple? What is the probable source in AI training data?
Hallucinated adverse events that appear across multiple LLMs and can be traced to a specific high-engagement forum thread represent a different risk category than a single anomalous ChatGPT output. The SOP needs to distinguish between them.
The Competitive Intelligence Dimension: What Competitor AI Profiles Reveal
Reading Competitor Drug AI Sentiment as a Market Signal
If a competing drug has declining AI sentiment—more negative framing, more safety hedging, more generic substitution recommendations—that reflects something happening in the information environment around that drug. It may be adverse event signals accumulating in patient communities. It may be negative clinical trial results generating news coverage. It may be a litigation story gaining traction. Whatever the cause, the AI sentiment shift is detectable before it shows up in prescription data.
Tracking competitor AI sentiment isn’t just interesting. It’s actionable intelligence for your own commercial strategy, your medical affairs positioning, and your regulatory watchfulness.
How AI Search Visibility Differs From Traditional Branded Search
Traditional branded search measures how often your drug’s name appears in search results and how it ranks. AI search visibility measures something different: when a user asks an AI model a question in your therapeutic area, does your drug appear in the answer, and how is it characterized?
These two metrics can diverge significantly. A drug can rank first in traditional search for its brand name but barely appear in AI answers to therapeutic area queries, because the AI’s training data or retrieval logic favors competitors. A drug with strong SEO may have weak AI share-of-voice if its content is optimized for traditional keyword ranking rather than for the conversational, synthesis-oriented format that AI models favor.
AI search visibility requires its own optimization strategy: content that answers the specific questions AI models are asked, structured in ways that AI models can extract and synthesize accurately, and distributed through channels that AI training pipelines and retrieval systems actually access.
Which Therapeutic Areas Face the Highest AI Misinformation Risk
Based on the intersection of training data composition, patient community size, and clinical complexity, five therapeutic areas carry the highest AI misinformation risk:
Obesity and metabolic disease: Cultural saturation combined with large patient communities and rapid drug class evolution creates high hallucination risk on indication boundaries and compounding equivalence.
Oncology: Complex, rapidly changing evidence base combined with emotionally intense patient communities and high off-label use creates high source contamination risk.
Mental health: Strong stigma-related online discussion combined with contested clinical evidence in some areas and high anecdote volume creates high sentiment contamination risk.
Pain management: The opioid policy landscape combined with addiction narrative dominance in public discourse and clinical nuance around chronic pain creates high framing risk.
Vaccines: Massive anti-vaccine content volume in training data combined with high-stakes public health context and emotionally polarized discourse creates high misinformation risk.
DrugPatentWatch, DrugChatter, and the Emerging AI Monitoring Ecosystem
How DrugPatentWatch Data Intersects With AI Drug Mentions
Patent expiry is one of the most reliable predictors of when AI-driven generic substitution recommendations will intensify. When a branded drug loses patent exclusivity, generic manufacturers enter, prices drop, generic names get more coverage in news and forums, and AI models start reflecting that shift in their generic recommendation frequency.
DrugPatentWatch tracks patent expiry and exclusivity status for the pharmaceutical pipeline. Integrating that timeline with your AI monitoring program gives you predictive insight: which of your drugs face AI generic substitution pressure in the next 12 to 36 months, and when should you expect AI outputs to begin shifting toward generic recommendation? Planning your content strategy and your AI monitoring intensity around patent expiry timelines is a more resource-efficient approach than uniform monitoring across your entire portfolio.
What an AI-Native Pharmaceutical Intelligence Platform Looks Like
The next generation of pharmaceutical market intelligence platforms will be AI-native in two senses: they’ll use AI to conduct analysis, and they’ll monitor AI systems as a primary data source. DrugChatter’s monitoring platform is built on this model, combining query-based LLM testing with structured pharmacovigilance-aligned reporting and competitive intelligence outputs.
These platforms need to solve four technical problems that general social listening tools don’t address: query reproducibility across AI platforms (ensuring the same query gets run in the same way each time), output versioning (tracking how the same query’s answer changes as models are updated), accuracy benchmarking against FDA-approved labeling, and hallucination classification at scale.
General-purpose social listening tools can detect mentions of your drug name in AI-generated content. They can’t tell you whether the AI’s answer about your drug is accurate, what the source type mix is in the response, or how your AI share-of-voice compares to competitors across specific query categories. That requires pharmaceutical-specific AI monitoring infrastructure.
How Physician Perception of Your Drug Is Being Shaped by AI
A 2024 survey by the American Medical Association found that 38% of physicians reported using AI tools at least weekly for clinical information queries, up from 14% in 2022. The most common use cases are literature search, clinical guideline lookup, and drug information queries. The least common is formal clinical decision support integrated into EHR workflows, which remains limited by implementation barriers.
This means a meaningful fraction of prescribers are receiving drug information filtered through LLMs that are not trained or validated for clinical decision support. Those LLMs blend clinical and anecdotal data in ways that a validated clinical decision support system would not. The physician using ChatGPT to check a drug interaction or a dosing threshold for an unfamiliar drug is receiving a different quality of information than the physician using Epocrates or Lexicomp.
In qualitative surveys and published clinical assessments, physicians consistently flag three reliability failures in AI drug information: outdated guideline citations, incorrect drug interaction rankings, and inconsistent off-label use framing. All three of these failure modes are exacerbated by the blending of clinical and anecdotal sources that characterizes current LLM behavior on drug queries.
Key Takeaways
AI language models do not distinguish between clinical trial data and patient anecdotes. They synthesize both into confident-sounding outputs, creating systematic accuracy problems for drug information across all major platforms.
Drugs with large, active patient communities online have their anecdotal experiences overrepresented in AI training data, creating sentiment and accuracy biases that differ systematically by drug and therapeutic area.
AI share-of-voice—how often and how favorably your drug appears in AI answers across ChatGPT, Gemini, Claude, and Perplexity—is a measurable, trackable metric that does not correlate cleanly with traditional branded search metrics.
AI hallucinations about drug safety create real regulatory and pharmacovigilance risks, even though FDA has not yet issued specific guidance on AI-generated drug information liability.
Pharmaceutical companies need AI monitoring programs distinct from social listening: structured query testing, accuracy benchmarking against approved labeling, and competitive share-of-voice tracking across multiple AI platforms.
Therapeutic areas with the highest AI misinformation risk are obesity, oncology, mental health, pain management, and vaccines—each for structurally different reasons related to training data composition and patient community characteristics.
Reddit’s elevated search ranking post-2023 means patient forum posts are now frequently the cited source in AI search answers, making Reddit monitoring an upstream pharmacovigilance function.
Patent expiry timelines reliably predict when AI generic substitution recommendation intensity will increase for a branded drug, enabling more efficient allocation of monitoring resources.
FAQ
What does it mean when an AI model blends clinical data with patient anecdotes about a drug?
It means the AI is producing a synthesized answer that draws on both peer-reviewed clinical trial evidence and informal patient-reported experiences from forums, social media, or news coverage, without distinguishing between them or signaling their different evidentiary weights. The result is an answer that may be partially accurate but presents information from sources of radically different reliability as if they carry equal authority. For pharmaceutical companies, this creates risks ranging from inaccurate safety information to misleading efficacy framing.
Can an AI hallucination about a drug create an FDA compliance problem for the drug company?
The direct regulatory liability is currently ambiguous because FDA has not issued specific guidance on AI-generated drug information. The indirect compliance risk is clearer: if a company knows an AI model is generating materially inaccurate safety information about its drug and takes no action, that creates a defensible gap in its pharmacovigilance and risk communication posture. Proactive monitoring and documented response to detected inaccuracies is the appropriate risk management approach under current FDA frameworks.
How do you measure AI share-of-voice for a pharmaceutical brand?
AI share-of-voice is measured by running a standardized battery of therapeutic area queries across multiple AI platforms—ChatGPT, Gemini, Claude, Perplexity at minimum—and scoring each output for drug mention frequency, favorability, accuracy, and competitive positioning relative to other drugs in the same class. Tracking these scores over time, across platforms, and against a defined competitor set produces a share-of-voice metric that reflects your drug’s relative position in AI-generated information for your therapeutic category.
Which AI platform is most accurate for drug information: ChatGPT, Gemini, Claude, or Perplexity?
Accuracy varies by drug, by query type, and over time. No single platform is uniformly most accurate for pharmaceutical information. Perplexity’s live retrieval means its accuracy tracks current web content, which can be high or low quality depending on what’s ranking. Claude tends to produce more conservative and hedged drug information outputs. ChatGPT reflects a large, diverse training corpus that includes significant patient forum content. Gemini’s accuracy for drug information has varied across model versions. Pharmaceutical companies should test all major platforms, because a drug’s accuracy profile often differs significantly across them.
What is the difference between social listening and AI monitoring for pharmaceutical brands?
Social listening captures what humans say about your drug in public digital spaces. AI monitoring captures what AI models say about your drug when directly queried. They are complementary but distinct disciplines. Social listening is retrospective: it records what was said. AI monitoring is active: you test what the AI will say in response to the queries your customers are actually making. Social listening tools track sentiment in human-generated content. AI monitoring benchmarks AI-generated content against approved labeling for factual accuracy. Both are necessary; only AI monitoring addresses the specific risk of AI-generated drug misinformation reaching patients and prescribers at scale.