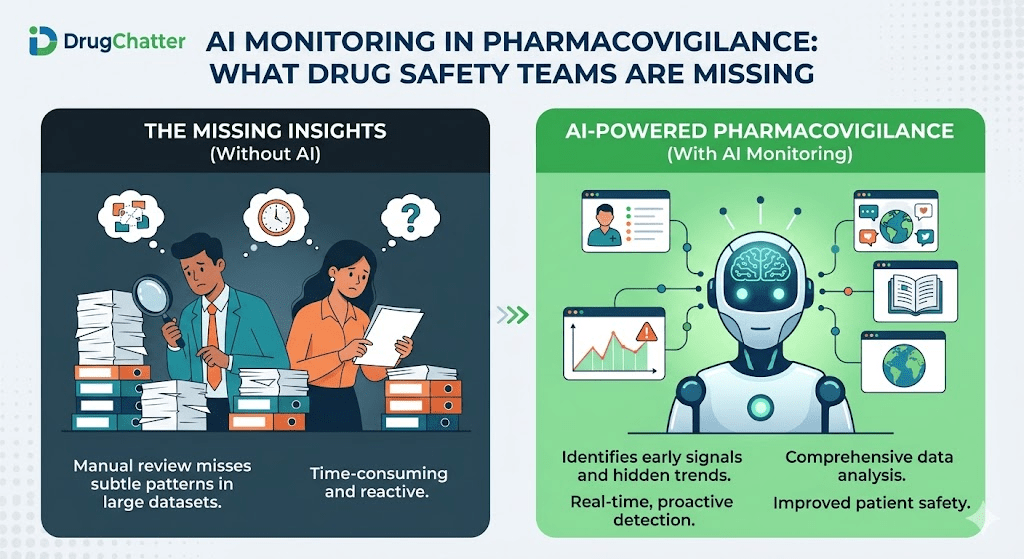
Drug safety surveillance has a new blind spot. Millions of patients are now asking ChatGPT, Gemini, Claude, and Perplexity about their medications — and the answers they get are not always accurate, not always on-label, and not always distinguishable from the product information a pharma company spent years and tens of millions of dollars to develop.
Pharmacovigilance teams have built mature pipelines for tracking adverse events on social media, in published literature, and through spontaneous reporting systems. Most of them have no systematic process for monitoring what large language models say about their drugs.
That gap is closing fast. Regulatory pressure, patient behavior shifts, and a growing body of evidence showing AI systems can and do produce incorrect drug safety information are pushing pharmaceutical companies to treat AI monitoring as a core function — not an experiment.
This article covers what pharmaceutical brand, safety, and medical affairs teams need to know about monitoring AI-generated content, where the regulatory exposure sits, and how to build a workflow that catches problems before they reach patients or regulators.
Why Patients Now Ask AI Instead of Their Doctor About Medications
The shift started before ChatGPT launched. Patients were already using Google, Reddit, WebMD, and patient forums to research their conditions. AI search changed the behavior pattern, not the underlying motivation.
What changed is the directness of the response. A Google search returns links. A ChatGPT query returns an answer, written in plain language, presented with confidence. Patients do not always check the sources — and many AI responses do not cite any.
How Patients Phrase Drug Questions in AI Search
The queries patients bring to AI systems look different from traditional search queries. They tend to be longer, more personal, and more clinically specific. Common patterns include:
‘Can I take [drug] with [other drug]?’
‘What happens if I miss a dose of [drug]?’
‘Why did my doctor prescribe [drug] for [off-label indication]?’
‘Is [brand name] the same as [generic]?’
‘What are the long-term side effects of [drug]?’
Each of these query types presents a different risk profile. Drug interaction queries carry direct safety implications. Off-label queries may surface information that the manufacturer cannot legally promote. Generic equivalence queries affect brand share. Long-term side effect queries may amplify or distort signals that safety teams are actively monitoring.
How Often Are Drugs Mentioned in AI Responses?
The frequency with which specific drugs appear in AI-generated responses depends on how extensively the underlying training data discusses that drug, how recently the model was trained, and how the query is structured. High-profile drugs like Ozempic (semaglutide), Humira (adalimumab), Eliquis (apixaban), and Keytruda (pembrolizumab) appear often in general health queries. Drugs with smaller market presence, niche indications, or recent approval may receive less coverage — and when they do appear, the information is more likely to be incomplete or out of date.
DrugChatter’s AI monitoring platform tracks drug mentions across major LLMs continuously, providing pharmaceutical companies with share-of-voice data, sentiment scoring, and safety claim analysis at scale.
Do LLMs Recommend Generic Drugs More Often Than Branded Drugs?
Several pharmaceutical brand teams have raised this question. The answer appears to be: sometimes, and it varies by model and query framing. When a patient asks ‘what is the best medication for type 2 diabetes,’ GPT-4 and similar models frequently lead with class-level responses (GLP-1 agonists, metformin) before mentioning specific drugs by brand or generic name. When branded drugs do appear, the model often includes a generic equivalent — sometimes in a way that implicitly frames the generic as the default choice.
This matters commercially. It also matters from a safety standpoint: branded drugs and their generics are bioequivalent by FDA definition, but they are not always interchangeable for every patient in every formulation. An AI system that defaults to generic substitution recommendations without acknowledging formulation-specific nuances can create patient safety concerns, particularly for narrow therapeutic index drugs like warfarin, levothyroxine, or lithium.
What AI Hallucinations About Drugs Actually Look Like
The term ‘hallucination’ covers a range of failure modes, from subtle inaccuracy to complete fabrication. In a pharmaceutical context, the most dangerous hallucinations are those that sound authoritative and relate to safety-critical information.
Why ChatGPT Gets Drug Side Effects Wrong
Large language models generate text based on statistical patterns in training data. They do not have access to a curated, current drug database. When a model generates a list of side effects for a given drug, it is producing a statistically plausible output — not retrieving validated safety information from a regulatory-approved source.
The result is that LLM-generated side effect profiles can include adverse events that are not in the FDA-approved label, omit serious adverse events that are in the label, assign incorrect frequency ratings, or conflate side effects across drugs in the same class. For a patient making a decision about whether to take a medication, any of these errors can be consequential.
Real Examples of Drug Misinformation in AI Outputs
Researchers have documented specific cases of AI-generated drug misinformation. A 2023 study published in JAMA Internal Medicine evaluated ChatGPT’s responses to common medication questions and found that while many responses were accurate, a meaningful proportion contained clinically important errors. The study noted particular problems with drug interaction queries, where the model sometimes failed to flag serious interactions documented in prescribing information.
A separate analysis by researchers at the University of California San Diego found that AI chatbots varied substantially in their accuracy when answering questions about cancer medications, with some models providing dosing guidance that diverged from approved labeling.
Can AI Hallucinations Trigger FDA Risk?
This is the question pharmaceutical legal and regulatory teams are increasingly asking — and the answer is more complex than a simple yes or no.
The FDA does not currently regulate the outputs of AI chatbots as drug labeling or promotional materials. But that regulatory distinction does not eliminate the risk. Consider the following scenarios:
A patient takes a drug based on information from an AI chatbot, experiences an adverse event, and a plaintiff’s attorney subpoenas the manufacturer’s awareness of AI misinformation about the drug.
The FDA receives adverse event reports that appear to reflect patient behavior influenced by incorrect AI-generated information about a drug — prompting a signal investigation.
A competitor’s drug is consistently described more favorably by major AI systems, affecting market access in ways the company cannot track without an AI monitoring program.
None of these scenarios is hypothetical. All three have credible near-term pathways to real impact. The question for drug safety teams is whether they want to find out about them reactively or proactively.
Off-Label Drug Discussions in LLMs: What Compliance Teams Need to Know
Off-label use is legal for physicians and patients. It is not legal for manufacturers to promote it. AI systems exist in a gray space: they discuss off-label uses based on published literature and internet content, and they do so without reference to manufacturer intent.
When an AI system accurately describes an off-label use of a drug based on published clinical evidence, that is not the manufacturer’s doing. But if a manufacturer becomes aware that AI systems are consistently recommending their drug for off-label indications — potentially exposing them to unwanted regulatory scrutiny — they need to know about it.
Conversely, if an AI system is describing off-label uses that are not supported by clinical evidence, or is generating safety information that conflicts with regulatory submissions, the manufacturer’s awareness (or lack thereof) becomes legally and reputationally relevant.
The Pharmacovigilance Gap: What Current Safety Systems Miss
Traditional pharmacovigilance infrastructure was built for a different information ecosystem. The core inputs — spontaneous adverse event reports, literature surveillance, clinical trial data, regulatory agency communications — remain essential. But they were designed before AI became a primary information source for patients and healthcare professionals.
How Traditional Pharmacovigilance Systems Work
The standard pharmacovigilance workflow begins with adverse event collection. Reports come from healthcare professionals, patients, literature, and partner organizations. These reports flow into safety databases, where they are coded, evaluated for causality, and assessed for signal. Significant signals trigger regulatory reporting obligations under ICH E2 guidelines and regional requirements (FDA’s FAERs system, EMA’s EudraVigilance).
Social listening has been layered onto this infrastructure over the past decade. Most large pharmaceutical companies now monitor Twitter/X, Facebook, Reddit, and patient forums for adverse event mentions. Natural language processing tools help identify valid adverse event reports in unstructured social media content. The FDA issued draft guidance on social media monitoring for pharmacovigilance in 2014, acknowledging the landscape had changed.
AI monitoring is the next layer. It is not a replacement for any existing component. It is an additional signal source that current PV systems are not designed to capture.
Can AI Outputs Be Used for Pharmacovigilance?
Technically, yes — with significant caveats. An AI system’s output about drug safety is not itself an adverse event report. It does not describe an individual patient experience. It is synthesized content based on training data of unknown recency and provenance.
But AI outputs can serve pharmacovigilance functions indirectly in several ways:
They can surface novel signal narratives — descriptions of adverse events or patient experiences that appear in AI training data but have not been captured in formal reporting systems.
They can reveal patterns in how patients are framing their symptoms and attributing them to medications, which can inform the design of patient-reported outcome instruments and adverse event intake forms.
They can flag when AI systems are amplifying specific adverse events in ways that may not reflect actual risk profiles — creating what amounts to an information-driven adverse event signal that safety teams need to track.
The ICH M14 guideline on signal management and the FDA’s real-world evidence framework both contemplate non-traditional data sources. AI monitoring fits within this evolving regulatory philosophy, even if it is not yet explicitly addressed in guidance documents.
What Pharma Brand Teams Can Learn From Reddit AI Citations
Reddit has become a significant source of patient-generated health content, and it is heavily represented in the training data of most major LLMs. This creates a specific problem: Reddit discussions about drugs are often authored by patients sharing personal experiences, which may include anecdotal adverse events, unofficial dose escalation practices, and off-label use discussions that conflict with prescribing information.
When an AI system cites Reddit — or when it has absorbed Reddit content into its training data — the resulting outputs may reflect the most vocal Reddit subpopulation rather than the average patient experience. Communities like r/diabetes, r/ChronicPain, r/bipolar, and r/pharmacy are active, sophisticated, and influential. They are also self-selected populations whose experiences may not be representative.
Brand teams that monitor AI outputs can identify when Reddit-amplified narratives are shaping AI responses about their drugs — and respond through medical information content strategies designed to provide balanced, evidence-based information in the channels AI systems actually index.
Tracking Share of Voice Across ChatGPT, Gemini, and Claude
Share-of-voice analysis has long been a standard tool for pharmaceutical brand teams. AI systems have created a new channel for SOV measurement — one that is arguably more influential than paid media, because patients perceive AI responses as objective information rather than advertising.
How AI Share-of-Voice Differs From Traditional Branded Search
In traditional branded search, share-of-voice is measured by who appears in organic or paid search results for relevant queries. A brand’s SOV is partly a function of its own SEO and paid search investment.
In AI search, the dynamics are fundamentally different. LLMs are not ranking pages — they are generating responses from internalized training data. A brand cannot buy its way into an AI response. It can, however, influence AI responses over time by ensuring that high-quality, factually accurate, authoritative content about its drug is available and indexable across the web.
This shifts the competitive intelligence question. The relevant question is not ‘where does our brand rank?’ but ‘what does the AI say about us relative to competitors, and what sources is it drawing on?’
How Often Does Claude Mention Ozempic vs. Wegovy?
Both Ozempic and Wegovy contain semaglutide and are manufactured by Novo Nordisk. Ozempic is approved for type 2 diabetes management. Wegovy is approved for weight management. They are frequently discussed interchangeably in media and patient forums, which creates AI response complexity.
In practice, AI systems tend to differentiate the two when queries are specific, but conflate them in general wellness and weight loss queries. A user asking ‘what is the best weight loss injection’ may receive a response that mentions Wegovy — or one that mentions Ozempic — depending on the model, the specific phrasing, and how the query is processed. For Novo Nordisk’s brand team, the distinction matters clinically and commercially. Monitoring which product an AI associates with which indication is a direct competitive intelligence function.
How Eli Lilly and Novo Nordisk Monitor AI Mentions
Neither Eli Lilly nor Novo Nordisk has published detailed disclosures about their AI monitoring programs. But based on publicly available procurement activity, conference presentations by medical affairs leaders, and the general state of enterprise AI tooling in pharma, the most sophisticated brand teams in GLP-1 are running systematic AI query programs to track how their drugs appear in major LLMs.
The basic architecture involves running predefined query sets against ChatGPT, Gemini, Claude, Perplexity, and Microsoft Copilot on a regular cadence. Responses are captured, parsed for brand mentions, safety claims, competitive comparisons, and dosing information, and compared against the approved label. Discrepancies are flagged for medical affairs review. Trends are reported to brand leadership on a monthly or quarterly basis.
More sophisticated programs add sentiment scoring, source attribution analysis, and physician-specific query monitoring. The goal is not just to know what AI says about a drug — it is to understand why it says it, and whether the inputs driving those outputs can be improved.
Comparing AI Share-of-Voice: GLP-1 Agonists as a Case Study
The GLP-1 agonist category is the most visible example of AI share-of-voice competition in recent pharmaceutical history. Semaglutide (Ozempic/Wegovy), tirzepatide (Mounjaro/Zepbound), and liraglutide (Victoza/Saxenda) are all active in media, patient forums, and AI training data. The competitive SOV picture in AI is significantly different from the competitive SOV picture in television advertising or print media.
Newer approvals — like tirzepatide for obesity — tend to be underrepresented in AI responses relative to their clinical performance, because training data lags real-world events. This creates a specific opportunity for brands with recent approvals: proactive content strategies designed to build AI-indexed evidence can accelerate the training data representation of new clinical information.
AI Monitoring Workflows: How to Build the Process
An effective pharmaceutical AI monitoring program has four core components: query design, response capture, analysis, and action.
Designing the Right Query Set for Drug Monitoring
Query design is the most underappreciated part of an AI monitoring program. The same underlying drug can generate very different AI responses depending on how the question is framed. A comprehensive query set should cover at least four query types:
Patient-perspective queries (‘What are the side effects of [drug]?’)
Physician-perspective queries (‘What is the mechanism of action of [drug]?’)
Comparative queries (‘[Drug A] vs [Drug B] for [indication]’)
Safety-specific queries (‘Is [drug] safe during pregnancy?’, ‘Can [drug] cause [specific AE]?’)
Each query type captures different aspects of AI representation. Safety-specific queries are the highest priority for pharmacovigilance functions. Comparative queries are the highest priority for brand teams. Physician-perspective queries matter most for medical affairs.
Which AI Systems Should Pharma Companies Monitor?
The answer depends on where patients and physicians are actually getting information. Current usage data suggests that ChatGPT (OpenAI) has the largest installed base of general health query users. Google Gemini is deeply integrated into Google Search via AI Overviews, making it the highest-reach AI system for health queries. Microsoft Copilot reaches the enterprise and healthcare professional audience through Bing and Microsoft 365. Perplexity is disproportionately used by technically sophisticated users, including many healthcare professionals. Claude (Anthropic) is increasingly common in enterprise deployments, including within healthcare organizations.
A minimum viable monitoring program covers ChatGPT and Gemini. A comprehensive program adds Perplexity and Claude. An advanced program includes model version tracking — because GPT-4o, GPT-4, and GPT-3.5 can return substantially different responses to the same drug query.
How to Detect Hallucinated Safety Claims About Your Drug
Detection requires comparison. Every AI response about a drug needs to be evaluated against the current approved label — the prescribing information (PI) or summary of product characteristics (SmPC). The evaluation should check:
Are stated indications consistent with the approved label?
Are stated contraindications complete and accurate?
Do stated warnings and precautions match label language?
Are adverse event frequencies accurate?
Are drug interaction warnings consistent with approved labeling?
Are dosing regimens correct?
This evaluation can be partially automated using NLP comparison against label text, but medical affairs or pharmacovigilance review of high-priority discrepancies remains essential. Automated systems can flag discrepancies. Qualified medical reviewers determine which discrepancies represent meaningful safety concerns.
Platforms like DrugChatter are purpose-built for this workflow, offering pharmaceutical-grade label comparison and structured discrepancy reporting.
What to Do When an AI System Is Spreading Drug Misinformation
The options available to pharmaceutical companies when they identify harmful AI misinformation about their drugs are more limited than most brand teams initially expect. LLM providers do not offer a formal process for manufacturers to correct drug information in model outputs analogous to a search engine’s structured data program.
The primary lever is content strategy: ensuring that high-quality, authoritative, factually accurate information about the drug is available in formats that AI systems index and cite. This means maintaining strong medical information resources, publishing in authoritative outlets, ensuring label information is machine-readable, and supporting physician education resources that become AI training data over time.
Some pharmaceutical companies have begun engaging directly with LLM providers through their enterprise relationships to flag systematic safety misinformation. This is not a formal regulatory mechanism, but it is a practical escalation path for serious cases.
Regulatory and Legal Exposure From AI Drug Content
The regulatory framework governing AI-generated drug content is still forming. That creates both opportunity and risk for pharmaceutical companies.
Does the FDA Hold Pharma Companies Responsible for AI Drug Claims?
The FDA’s current position, based on its 2023 discussion paper on AI/ML-based drug development and recent public statements by CDER leadership, is that manufacturers are not directly liable for AI-generated content that they did not create or control. The Office of Prescription Drug Promotion (OPDP) has not issued warning letters targeting AI-generated drug content as of mid-2025.
But the FDA’s position is evolving, and manufacturers that remain passive face several exposure pathways. If a company becomes aware that an AI system is systematically providing incorrect safety information about its drug and takes no action, that awareness could become relevant in adverse event litigation, citizen petition responses, or future regulatory proceedings.
The FDA’s spontaneous reporting system, FAERS, does not currently have a category for adverse events influenced by AI-generated misinformation. But MedWatch forms do capture the information source patients used — and as AI chatbot use grows, it is reasonable to expect more cases where AI-generated information played a role in patient behavior. Safety teams should be asking whether their current signal detection processes would identify this pattern.
EMA and International AI Pharmacovigilance Standards
The European Medicines Agency has been more explicit than the FDA about AI’s role in pharmacovigilance. EMA’s 2023 reflection paper on the use of artificial intelligence in the medicinal product lifecycle identified signal detection as one of the highest-priority applications for AI governance. The EMA’s pharmacovigilance working party has flagged social media and patient-generated digital content — which now includes AI interactions — as emerging signal sources requiring regulatory attention.
For companies with products registered in the EU, this has practical implications. EMA’s Good Pharmacovigilance Practices (GVP) modules already require systematic monitoring of literature and digital sources. The question of whether AI-generated content falls within that requirement will likely be clarified in GVP module revisions currently in development.
Litigation Risk: When AI Drug Misinformation Causes Harm
Product liability law in the United States does not yet have established precedent for AI-mediated drug misinformation. But plaintiff attorneys are actively exploring the theory. The logical argument is that a manufacturer who is aware that AI systems are providing dangerous misinformation about its drug — and who fails to take reasonable steps to correct the record — may have a duty-to-warn exposure.
This theory has not been tested in court as of this writing. But the discovery implications are already real: legal teams advising pharmaceutical companies are now asking whether their clients have monitoring programs that would create a record of awareness. A company with no monitoring program cannot be shown to have ignored evidence it never collected. A company with a monitoring program that failed to act on documented misinformation faces a different calculus.
‘Eighty-three percent of patients who received incorrect medication information from an AI chatbot in a 2024 patient safety survey said they would have acted on it without consulting their physician or pharmacist.’ — Patient Safety Technology Collaborative, Annual AI Health Survey 2024
Physician and Patient Sentiment in AI Responses
AI monitoring is not only about adverse events and regulatory compliance. It is also a voice-of-the-customer function — one that captures how patients and physicians are thinking about drugs through the questions they bring to AI systems and the responses those systems generate.
How Physician Perception Appears in AI Drug Responses
AI training data includes medical literature, conference proceedings, clinical guidelines, and physician commentary published across professional channels. This means AI responses about drugs carry embedded physician sentiment — often reflecting the consensus view as of the model’s training cutoff, but sometimes reflecting specific clinical controversies, therapeutic debates, or minority perspectives that have outsized representation in the literature.
A drug that faced significant physician skepticism at launch — even if that skepticism was subsequently resolved by outcomes data — may still encounter that skepticism in AI responses if the training data is older than the resolution. Medical affairs teams monitoring AI responses can identify when outdated physician sentiment is shaping patient-facing AI content, and respond with updated evidence strategies.
How to Track Emerging Patient Concerns Before They Trend
Patient-facing AI queries are a leading indicator of patient concern. When patients begin asking AI systems about a specific adverse event or clinical concern that has not yet appeared in spontaneous reports or social media monitoring, it may indicate an emerging issue that traditional surveillance is not yet capturing.
This early warning function is one of the most practically valuable aspects of AI monitoring for pharmacovigilance teams. It does not replace traditional signal detection — it provides an additional upstream signal that may arrive earlier in the patient experience pathway.
For example: if a significant number of patients begin asking AI systems ‘does [drug] cause hair loss?’ before that concern appears at material frequency in FAERS or social listening platforms, that query pattern is itself a signal. It suggests the concern is present in the patient population even if it has not yet generated formal adverse event reports.
AI Query Patterns by Therapeutic Area
Patient query behavior in AI systems varies significantly by therapeutic area. Oncology patients tend to ask more mechanistic questions (‘how does [drug] target cancer cells?’) and more survival-focused questions (‘how effective is [drug] for [cancer type]?’). Patients with chronic conditions like rheumatoid arthritis or Crohn’s disease tend to ask more lifestyle questions (‘can I exercise while taking [drug]?’) and more comparative questions (‘is [drug] better than [competitor]?’).
Mental health medication queries follow a pattern that should concern pharmacovigilance teams: patients frequently ask AI systems about discontinuation, dosing adjustments, and drug interactions — all areas where AI hallucination risk is high and where incorrect information can have serious consequences.
The AI Citation Problem: Where Do LLMs Get Drug Information?
Understanding what an LLM says about a drug is only half the problem. Understanding where it gets that information is the other half — and it is considerably harder.
How AI Systems Source Drug Information
Most major LLMs are trained on internet-scale datasets that include FDA.gov, drug manufacturer websites, PubMed, WebMD, Drugs.com, RxList, patient advocacy sites, Reddit, news articles, and academic publications. The relative weight given to each source type is not publicly disclosed by most model developers. Retrieval-augmented generation (RAG) systems can also pull from live web content — which means that for AI systems with web access, the information source set is more current but also more variable and less predictable.
Some AI systems, particularly in healthcare-specific deployments, are being fine-tuned on curated medical knowledge bases. These deployments carry lower hallucination risk for drug information, but they represent a small fraction of patient and physician AI interactions.
Why AI Drug Information Lags Behind Label Updates
Model training cutoffs create a systematic lag between current labeling and AI-generated drug information. When the FDA approves a new indication, requires a new boxed warning, or modifies a drug’s risk evaluation and mitigation strategy (REMS), the approved label changes immediately. AI systems trained before that change will continue to generate responses based on pre-update information — potentially for months or years after the regulatory event.
This lag is not trivial. Boxed warnings added after initial approval reflect serious new safety information. An AI system that does not include a boxed warning in its description of a drug’s safety profile is providing materially incomplete — and potentially dangerous — information to patients asking about that drug.
Drug patent watch data and FDA approval records can be used to identify specific label update events and then audit AI responses to determine whether those updates are reflected. DrugChatter’s monitoring platform tracks label versions against AI responses as a core workflow feature.
Analyzing AI Citation Sources for Competitive Intelligence
AI systems that cite their sources — Perplexity being the most systematic about this — provide pharmaceutical brand teams with direct intelligence about which authoritative content is driving AI responses. If a competitor’s clinical trial data, published in a high-impact journal, is consistently cited in AI responses recommending that competitor’s drug, that is actionable intelligence. It tells the brand team where the competitive advantage in AI search is being generated, and where they need to build content authority to compete.
Building an AI Monitoring Program: Practical Steps for Pharma Teams
A pharmaceutical AI monitoring program does not have to be a large-scale technology investment to deliver value. A structured, systematic approach can be implemented by a team of two to three people using purpose-built monitoring tools, with results that feed directly into existing pharmacovigilance, medical affairs, and brand management workflows.
Where to Start: Prioritizing Drugs for AI Monitoring
Not every drug in a company’s portfolio requires the same level of AI monitoring. Prioritization should consider:
Patient volume: High-volume drugs generate more patient queries to AI systems, and therefore face greater risk from AI misinformation.
Therapeutic risk: Drugs with narrow therapeutic indices, serious safety profiles, or complex dosing regimens carry higher stakes if AI-generated information is incorrect.
Competitive landscape: Drugs in competitive categories where AI share-of-voice may affect prescribing decisions warrant brand-focused monitoring.
Recent label changes: Drugs that have had recent label updates — new warnings, new indications, REMS modifications — are at highest risk for AI-generated information that does not reflect current labeling.
How to Measure ROI on Pharmaceutical AI Monitoring
Return on investment for AI monitoring is measurable along three dimensions. The first is risk avoidance: identifying and addressing AI misinformation about serious safety concerns before it generates adverse event reports, litigation exposure, or regulatory scrutiny. The second is brand value: tracking and improving AI share-of-voice in high-reach AI systems where patient and physician decisions are influenced. The third is intelligence value: understanding patient and physician query patterns that inform medical education strategy, label communication, and patient support program design.
Quantifying risk avoidance is inherently difficult. Quantifying brand value requires a share-of-voice baseline and a measurement framework. Quantifying intelligence value is best done by tracking downstream use of AI monitoring insights in medical affairs and brand planning decisions.
Integrating AI Monitoring Into Existing PV Systems
The practical integration question is where AI monitoring outputs flow in an existing pharmacovigilance infrastructure. The recommended approach is to treat AI monitoring as an additional signal source that feeds the same signal management process as social media monitoring and literature surveillance.
AI responses that contain potentially valid adverse event information should be evaluated by trained pharmacovigilance staff using the same four-element assessment framework (identifiable reporter, identifiable patient, identifiable drug, adverse event) used for social media signals. Most AI-generated content will not meet all four criteria, because AI responses describe general drug information rather than individual patient experiences. But AI responses that reproduce specific patient anecdotes from their training data — which does happen — may meet the criteria for individual case safety report (ICSR) assessment.
A formal SOPs for AI monitoring signal intake, triage, and escalation should be developed alongside the monitoring program itself.
What the Future of AI Drug Monitoring Looks Like
The pharmaceutical industry’s AI monitoring capability is roughly where social media pharmacovigilance was in 2012: important, recognized as important, and still largely absent from formal regulatory frameworks. The regulatory frameworks will come. The question is whether drug safety teams are building the internal capability and institutional knowledge to be ready when they do.
How Regulatory Agencies Are Approaching AI and Drug Safety
FDA’s Center for Drug Evaluation and Research has been studying AI’s role in pharmacovigilance for several years. The 2021 AI/ML action plan and subsequent discussion papers signal an agency that is moving methodically toward formal guidance. The most likely near-term regulatory development is inclusion of AI-generated content in expanded social listening guidance — treating AI interactions as a form of patient-reported health content subject to existing adverse event surveillance obligations.
EMA’s position may crystallize faster. The EU’s AI Act, which became effective in 2024, includes provisions relevant to high-risk AI applications in healthcare. While the Act primarily targets AI system developers, its risk classification framework may influence how pharmaceutical companies document their AI monitoring activities as part of their quality management systems.
The Role of Retrieval-Augmented Generation in Pharmaceutical AI
Retrieval-augmented generation systems — where an LLM draws on a live knowledge base rather than solely on training data — represent a significant improvement in drug information accuracy when the knowledge base is well-curated. Several healthcare AI startups and established health IT companies are building RAG-based systems explicitly designed for clinical decision support and patient education, with drug databases as core knowledge sources.
As RAG-based AI becomes more prevalent in clinical settings, pharmaceutical companies have a new leverage point: ensuring their drug information is available in formats optimized for RAG indexing. This is a content strategy and data engineering function that will require collaboration between medical affairs, regulatory, and digital teams.
AI Monitoring and Real-World Evidence: The Long Game
Real-world evidence programs are increasingly central to pharmaceutical development and post-approval strategy. AI monitoring — particularly the analysis of patient query patterns and sentiment in AI interactions — is a potential source of real-world insight that complements traditional RWE data sources like electronic health records, insurance claims, and patient registries.
AI query data captures something that EHR data and claims data do not: the patient’s unmediated experience of living with a drug, expressed in their own language, at the moment of need. That information has value for product lifecycle management, label communication, and patient support program design that is independent of its pharmacovigilance applications.
Key Takeaways
AI systems including ChatGPT, Gemini, Claude, and Perplexity are now primary drug information sources for millions of patients — and their outputs frequently contain clinically significant inaccuracies.
Pharmacovigilance teams face a blind spot: current adverse event surveillance infrastructure was built before AI became a mainstream patient information channel. AI monitoring closes that gap.
The most serious risk from AI drug misinformation involves safety-critical content: adverse events, contraindications, drug interactions, and dosing — areas where AI hallucinations can directly influence patient behavior.
Model training cutoffs create systematic lags between current drug labeling (including new boxed warnings) and AI-generated drug information. Monitoring programs should prioritize drugs with recent label changes.
AI share-of-voice is a new competitive metric. Which drugs appear in AI responses, in what context, and with what comparative framing directly affects patient and physician decision-making.
Off-label AI content is a compliance consideration: AI systems discuss off-label uses based on published literature, and manufacturers need to know when and how their drugs are appearing in those discussions.
The regulatory framework for pharmaceutical AI monitoring is still forming. Companies that build monitoring programs now will be positioned to comply with forthcoming FDA and EMA guidance without disruption.
Integration with existing PV systems is achievable. AI monitoring outputs should flow into the same signal management process as social media and literature surveillance.
Platforms like DrugChatter are purpose-built for pharmaceutical AI monitoring — offering label comparison, share-of-voice tracking, sentiment analysis, and discrepancy reporting at the scale drug safety teams need.
Frequently Asked Questions
What is AI monitoring in pharmacovigilance?
AI monitoring in pharmacovigilance refers to the systematic surveillance of AI-generated content — including outputs from ChatGPT, Gemini, Claude, and Perplexity — for drug-related information that may contain safety misinformation, inaccurate adverse event descriptions, off-label recommendations, or content that diverges from FDA-approved labeling. It functions as an additional signal source alongside social media monitoring, literature surveillance, and spontaneous adverse event reporting.
Are pharmaceutical companies legally responsible for what AI says about their drugs?
As of mid-2025, the FDA has not held pharmaceutical manufacturers directly liable for AI-generated drug content they did not create. But legal exposure exists through product liability theory if a company becomes aware of systematic safety misinformation about its drug and fails to take reasonable corrective steps. Discovery risk in drug litigation now routinely includes questions about a manufacturer’s awareness of AI-generated drug content.
How accurate is ChatGPT when answering drug side effect questions?
Accuracy varies by drug and query type. Peer-reviewed research has documented clinically significant errors in ChatGPT drug responses, including incorrect adverse event frequency descriptions, missed serious adverse events, and inaccurate drug interaction warnings. The error rate is highest for drugs with recent label changes, complex safety profiles, and limited representation in training data. AI systems with real-time web access (like Perplexity) tend to have more current information but introduce different accuracy risks from variable web sources.
Can AI monitoring replace traditional social media pharmacovigilance?
No. AI monitoring is a complementary signal source, not a replacement. Social media pharmacovigilance captures authentic individual patient experiences reported in real time. AI monitoring captures synthesized responses that may reflect aggregated patient experience but rarely meet the four-element criteria for an individual case safety report. Both are needed. AI monitoring’s unique value is in detecting label discrepancies, tracking share-of-voice, identifying query patterns, and providing an early warning function for emerging patient concerns.
How often should pharmaceutical companies run AI monitoring queries?
For high-priority drugs — those with large patient populations, serious safety profiles, or recent label changes — weekly monitoring is appropriate. For lower-priority drugs in a broader portfolio, monthly monitoring provides a reasonable signal-to-cost ratio. Event-triggered monitoring (running queries immediately after an FDA label update, a new safety communication, or a significant media event) should be added to any cadence-based program. Model updates from AI providers should also trigger targeted re-monitoring, since a model version update can substantially change drug response outputs.
Get sharp analysis on AI-generated drug information, off-label curiosity, pharmacovigilance blind spots, and the shifting intersection of pharma, search, and large language models. No fluff. Just the signals that matter.