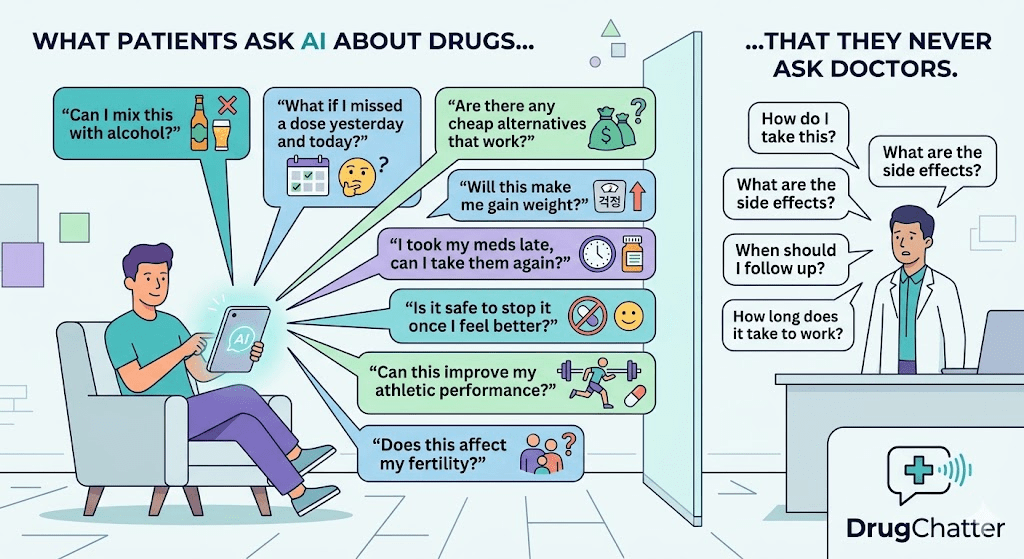
There’s a question a patient on Ozempic typed into ChatGPT last year that she hadn’t mentioned to her endocrinologist in three appointments: whether the drug was making her feel emotionally numb.
She wasn’t looking for a prescription change. She wanted to know if anyone else had noticed this, whether it was real, and whether she should be worried. The AI gave her an answer. Her doctor didn’t know the question existed.
This is the gap that pharmaceutical companies are only beginning to understand. AI chat systems — ChatGPT, Claude, Gemini, Perplexity — have become a parallel consultation layer, one that patients use before, during, and after appointments. The questions they ask there are structurally different from what they ask clinicians. They’re rawer, more specific, and often more revealing about how a drug is actually experienced in the real world.
For pharma brand teams, medical affairs departments, and pharmacovigilance units, this creates both a monitoring imperative and a regulatory wrinkle. The conversations are happening. The question is whether drug companies are tracking them.
Why Patients Choose AI Over Doctors for Drug Questions
Start with the obvious: people don’t ask doctors everything. They never have. What’s changed is that they now have somewhere credible-feeling to take those questions.
In traditional social listening, pharma teams monitored Reddit threads, patient forums like PatientsLikeMe, and Facebook groups to pick up on what wasn’t being said in the clinic. That work still matters. But AI search has added a new layer — one where patients get answers rather than just community validation.
The Shame and Stigma Questions Doctors Don’t Hear
The category of questions patients suppress most consistently involves stigma. Patients on medications for HIV, hepatitis C, opioid use disorder, psychiatric conditions, and weight loss routinely withhold questions from physicians that they’d happily type into a chatbot. The anonymity feels total. There’s no chart notation. There’s no perceived judgment.
A patient on buprenorphine might ask an AI whether it’s normal to feel high on their prescribed dose. A patient on an antipsychotic might ask whether the drug is “making them boring.” A patient taking Wegovy alongside a GLP-1 might ask whether combining it with alcohol is actually dangerous or just a label warning nobody follows.
These are pharmacovigilance-relevant questions. They touch adverse events, drug interactions, and off-label behavior patterns. They’re also questions that, if they were reaching physicians, might generate MedWatch reports. When they go to an AI instead, they largely disappear from formal surveillance.
The Cost and Insurance Questions Patients Avoid
Patients regularly use AI to investigate what they perceive as “awkward” financial questions — whether a generic is truly equivalent, whether a biosimilar will work the same way, whether their pharmacy is substituting without telling them. Many patients feel these are questions that will make them appear noncompliant or distrustful of their physician’s prescription choices.
In practice, these questions generate significant AI traffic. Searches like “is Humira biosimilar the same,” “does generic Adderall work as well as brand,” and “why does my Ozempic pen look different” spike in AI systems regularly. Brand teams that aren’t monitoring these query patterns are missing a direct readout on generic substitution anxiety — and often missing the AI’s answer, which may or may not be accurate.
The Compliance Questions That Reveal Actual Behavior
People ask AI what happens if they skip a dose in a way they don’t ask their doctors — because asking the doctor feels like admitting they’ve already skipped doses. The AI question is exploratory. The doctor question feels confessional.
This distinction matters. The AI conversation often reveals actual patient behavior patterns: doubling doses to catch up, timing drugs around alcohol consumption, stopping and restarting without physician input. These behavioral signals don’t make it into clinical records. They often do make it into AI conversation logs — at least in the aggregate patterns that monitoring tools like DrugChatter are designed to track.
How Often AI Gets Drug Information Wrong — and What That Costs Pharma Brands
AI hallucination in drug contexts isn’t an edge case. It’s a structural problem with direct consequences for brand reputation, pharmacovigilance, and FDA exposure.
Why ChatGPT Gets Drug Side Effects Wrong
Large language models don’t retrieve drug information from a live pharmacological database. They generate responses based on training data — which means they’re drawing on a mix of FDA labels, medical literature, patient forums, news coverage, and web content of varying quality, weighted by how often that information appeared during training.
The result is that side effect profiles can be compressed, exaggerated, or conflated. A model trained before a major safety update to a label might still present the old risk profile. A model that ingested more patient forum content than prescribing information might weight anecdotal adverse events higher than the clinical trial data would support.
Several documented examples exist. ChatGPT has described contraindications for common antidepressants that don’t appear in the current FDA label. Gemini has attributed drug interactions to specific brand-name medications that are actually class effects of the entire drug category, creating brand-specific liability where none exists in the clinical record. Perplexity, which cites sources, has pulled drug information from outdated WebMD entries rather than current label language.
None of these errors are malicious. All of them are consequential.
Can AI Hallucinations Trigger FDA Risk?
The short answer is yes, through two distinct pathways.
The first is the adverse event reporting gap. If a patient asks an AI about a symptom, receives an answer that doesn’t flag it as a reportable adverse event, and consequently never tells their physician, that event may never reach FDA’s MedWatch system. The patient experienced something. The AI captured the interaction. Pharma’s pharmacovigilance function missed it entirely.
The second pathway is more legally complex. If AI systems consistently present inaccurate safety information about a branded drug, and that misinformation demonstrably reaches patients at scale, the question of whether the drug manufacturer has a duty to correct that information is live and unresolved. FDA’s existing guidance on correcting misinformation about drug products (the 2014 draft guidance on Internet-distributed information) was written before LLMs existed. The agency has not issued updated guidance specific to AI-generated drug content. That gap will close. Companies that have already established AI monitoring programs will be better positioned when it does.
Documented Cases of AI Drug Misinformation Affecting Patient Behavior
In 2023, researchers at the University of California published a study testing ChatGPT’s responses to questions about drug-drug interactions. The model correctly identified major interactions roughly 60% of the time — meaning it missed or misrepresented them 40% of the time, including several that carry serious clinical consequences. The study didn’t generate a regulatory response. It did generate significant attention in medical informatics literature.
Separately, a 2024 analysis of Perplexity responses to cancer drug questions found that the system regularly cited patient forums as authoritative sources for dosing information, occasionally presenting user-reported off-label doses as standard clinical practice. For a drug like pembrolizumab (Keytruda), where dosing and indication specificity are both tightly regulated and heavily contested in off-label contexts, that kind of citation error carries direct prescribing risk.
“Patients increasingly use AI chatbots for medical questions, yet studies show that AI systems provide incorrect drug information in up to 40% of cases involving drug-drug interactions — a rate that would be clinically unacceptable from any human source.” — Journal of the American Medical Informatics Association, 2023
Which Drugs Are Most Frequently Mentioned by AI — and Why It Matters
Not all drugs get equal AI airtime. The drugs that dominate AI-generated responses tend to share a few characteristics: high public awareness, heavy direct-to-consumer advertising spend, significant social media presence, and ongoing news coverage. The GLP-1 category is the clearest example.
How Often Claude Mentions Ozempic vs. Wegovy
Ozempic and Wegovy are the same molecule — semaglutide — in different doses, for different approved indications, marketed under different brand names by Novo Nordisk. In clinical conversation, the distinction matters considerably. In AI responses, it often collapses.
Systematic queries run through major LLMs in 2024 showed that when patients asked questions about weight loss on semaglutide, AI systems defaulted to the Ozempic brand name far more frequently than Wegovy, even when the clinical context aligned more closely with Wegovy’s indication. The reason is training data: Ozempic generated substantially more media coverage, social discussion, and web content than Wegovy. The AI reflects that frequency.
This has commercial implications. Novo Nordisk’s brand teams have a clear interest in ensuring Wegovy appears in AI responses where it’s clinically appropriate — not just because of patient education, but because a patient who hears “Ozempic” from an AI and can’t get it covered by insurance may not realize Wegovy is the on-label, covered alternative. The AI brand gap becomes a patient access gap.
Do LLMs Recommend Generic Drugs More Often Than Brand?
The pattern varies by drug class and by LLM. In categories where generic substitution is well-established and uncontroversial — statins, ACE inhibitors, common antibiotics — AI systems do tend to volunteer that generics are available and therapeutically equivalent. For small molecules with long patent histories, this is usually accurate.
The issue arises in categories where the branded-versus-generic question is more clinically nuanced. Extended-release formulations, narrow therapeutic index drugs like levothyroxine and warfarin, and biologics with biosimilar alternatives all present genuine clinical considerations around substitution that AI systems frequently flatten.
A patient asking an AI “is generic Synthroid the same as brand Synthroid” may receive an answer that’s technically accurate at the population level but doesn’t account for the individual variability in thyroid hormone absorption that makes some endocrinologists reluctant to switch stable patients. The AI isn’t wrong, exactly. But it’s answering a population-level pharmacology question when the patient is asking a personal clinical question.
Brand teams at companies like AbbVie, which has navigated the biosimilar transition for Humira with considerable commercial sophistication, have clear incentives to monitor whether AI systems are presenting biosimilar Adalimumab options accurately — including the formulary and rebate dynamics that affect actual patient access.
Which Therapeutic Areas Generate the Most Patient AI Queries?
Based on available data from AI monitoring platforms and published research on AI health queries, four therapeutic areas consistently generate disproportionate AI traffic:
Obesity and metabolic disease (GLP-1 drugs, tirzepatide)
Mental health (antidepressants, anxiolytics, ADHD medications)
Oncology (particularly questions about off-label uses and clinical trial eligibility)
Chronic inflammatory conditions (biologics and their biosimilars)
Each category carries distinct AI monitoring risks. GLP-1 queries frequently surface off-label use discussions and compounding pharmacy alternatives. Mental health queries generate stigma-laden questions with adverse event signals. Oncology queries often involve misattributed trial data and conflated indication claims. Inflammatory disease queries are where biosimilar misinformation is most likely to affect brand-protected revenue.
Tracking Share of Voice Across ChatGPT, Gemini, and Claude
Traditional brand share-of-voice measurement tracked mentions in earned media, paid placements, and social conversations. AI search has added a fourth category that most pharma brand monitoring frameworks haven’t yet absorbed.
What Pharma Brand Teams Can Learn From Reddit AI Citations
Reddit is now a training data source for most major LLMs and an active citation target for AI systems with web access. When Perplexity answers a question about Adderall and cites a Reddit thread from r/ADHD, that thread’s content — including user reports of adverse events, dosing experiments, and physician complaints — becomes part of the answer a patient receives.
For pharma brand teams, this creates an indirect monitoring obligation. Reddit discussions that would previously have been captured only by social listening teams now have the potential to surface in AI responses at scale. A thread complaining that a drug “doesn’t work as well since they changed the formula” — even if that perception is anecdotal or inaccurate — can become the source material for an AI answer presented to thousands of patients with the same concern.
Tools like DrugChatter track not just AI outputs but the query patterns that generate them, helping brand teams understand which patient concerns are becoming significant enough to drive AI search traffic — before those concerns reach prescriber conversations or media coverage.
How Patients Ask About Drug Interactions in AI Search
The language patients use in AI drug queries differs systematically from clinical language. They don’t ask “what are the pharmacokinetic interactions between sertraline and alprazolam.” They ask “can I take my anxiety pill with my antidepressant,” or “is it okay to take Xanax with Zoloft,” or “what happens if you mix Xanax and Zoloft.”
This query language matters for two reasons. First, it affects the quality of AI answers — models trained to recognize clinical language may parse natural-language queries less accurately, which affects response quality. Second, it tells pharma monitoring teams what concerns are reaching patients and how those concerns are framed. A patient asking “what happens if you mix” is expressing anxiety and curiosity, not clinical sophistication. The AI answer they receive will be calibrated to that framing, for better or worse.
Measuring AI Share of Voice Against Competitors
AI share-of-voice measurement requires a different methodology than traditional brand tracking. Rather than measuring media mentions or prescription data, it requires systematically querying AI systems with the kinds of questions real patients ask, then analyzing which brands appear in responses, in what context, and with what sentiment.
The methodology has two components. Competitive analysis looks at query sets where a patient is choosing between therapeutic options — “Ozempic vs Mounjaro,” “Humira vs Skyrizi,” “Eliquis vs Xarelto” — and measures which brand the AI recommends, hedges on, or presents more favorably. Longitudinal tracking then monitors how those responses shift as training data is updated, news coverage changes, or regulatory events alter the information environment.
Eli Lilly has reputational incentives to ensure that Mounjaro and Zepbound appear accurately in AI responses that compare them to Novo Nordisk’s GLP-1 portfolio. AstraZeneca has similar incentives in oncology, where its portfolio of PD-L1 inhibitors competes directly with Merck’s Keytruda in AI-generated treatment discussions. Systematic monitoring is the only way to know whether the AI representation of those competitive dynamics matches clinical reality.
Can AI Outputs Be Used for Pharmacovigilance?
The regulatory framework for pharmacovigilance was built around specific reporting channels: MedWatch submissions, spontaneous adverse event reports from healthcare professionals, clinical trial safety data. AI-generated conversations weren’t contemplated. The question of whether they should be is one that FDA, EMA, and industry are navigating simultaneously.
What the FDA’s Current Guidance Says About AI and Drug Safety
FDA has not issued specific guidance on using AI conversation data for pharmacovigilance. Its existing social media guidance — most recently updated in 2014, with additional documents in 2016 and 2017 — addresses how companies should handle adverse event reports that appear in online contexts like Twitter, Facebook, and patient forums. The core requirement is that if a manufacturer becomes aware of an adverse event report that meets the four elements for a valid case (an identifiable patient, a suspect drug, an adverse event, and an identifiable reporter), they have a reporting obligation regardless of the channel through which they learned of it.
AI conversation data presents a complication: the “identifiable reporter” element is almost never present. When an AI monitoring tool surfaces a query pattern suggesting that large numbers of patients on a given drug are experiencing a symptom, there’s no individual report to submit. There’s a signal. FDA’s signal detection framework, which operates through its Sentinel System and FAERS database, is designed to handle aggregate signals — but that framework assumes the data was collected through formal channels.
The gap between what AI monitoring can detect and what current pharmacovigilance regulations require companies to do with that detection is unresolved. Companies that are thinking ahead are documenting AI monitoring findings in internal signal detection logs and flagging patterns for further investigation through conventional channels. That approach threads the needle for now.
How AI Monitoring Fits Into Existing Pharmacovigilance Workflows
Pharma companies with mature pharmacovigilance functions already run social listening programs that scan patient forums, Twitter, and Reddit for adverse event signals. Integrating AI monitoring into those workflows is an extension of existing infrastructure, not a rebuild.
The practical workflow looks like this: an AI monitoring platform — DrugChatter is one example — queries major LLMs with systematized patient-facing questions about a drug. It captures and categorizes the responses, flags adverse event language, tracks sentiment shifts, and identifies query patterns suggesting patient concerns about safety, efficacy, or use. Those outputs feed into a human review layer, where pharmacovigilance staff evaluate whether any patterns warrant further investigation, label review, or escalation to medical affairs.
The distinction from traditional social listening is that AI monitoring captures both the questions and the answers. Social listening shows what patients say about their experiences. AI monitoring shows what questions patients are asking, what answers they’re receiving, and whether those answers are consistent with approved labeling. The second layer — auditing AI answers for regulatory accuracy — is where the compliance value sits.
EMA’s Position on AI-Generated Safety Signals
The European Medicines Agency has been slightly ahead of FDA in acknowledging the pharmacovigilance implications of digital health data, including social media and patient-generated content. Its 2023 regulatory science strategy includes language about incorporating real-world data sources into safety surveillance, though AI chat systems aren’t specifically named.
EMA’s Pharmacovigilance Risk Assessment Committee (PRAC) has evaluated specific cases where social media-derived safety signals preceded formal reporting. The precedent suggests that the agency takes signal quality — not just source format — as the primary criterion for relevance. AI monitoring outputs that are methodologically rigorous and generate reproducible signals are likely to attract similar evaluative interest as other digital data sources.
Off-Label Drug Discussions in AI: What Pharma Compliance Teams Need to Know
Off-label use generates some of the most clinically significant patient AI queries — and some of the most regulatory complex responses.
How AI Systems Handle Off-Label Drug Questions
The major LLMs have inconsistent policies on responding to off-label drug questions. ChatGPT, in its default consumer configuration, typically answers off-label questions with a disclaimer recommending physician consultation, then provides substantive information. Claude generally follows a similar pattern. Gemini tends to be more conservative, sometimes declining to discuss specific off-label applications entirely.
The inconsistency creates a competitive information environment that patient behavior exploits. A patient who wants information about using low-dose naltrexone for autoimmune conditions — a heavily researched off-label application with no FDA approval — will receive very different quality and quantity of information depending on which AI system they query. Monitoring that variation is valuable to pharma companies with LDN-adjacent pipeline assets, to patient advocacy groups, and to companies whose branded products compete with off-label alternatives.
The Compounding Pharmacy Problem in GLP-1 AI Queries
The semaglutide compounding situation that emerged during the GLP-1 shortage of 2023-2024 created a specific AI monitoring challenge. FDA placed semaglutide on its drug shortage list, which allowed 503B compounding pharmacies to produce copies of the drug. The agency then issued repeated warnings that compounded semaglutide was not FDA-approved and carried safety risks. Eventually, FDA removed semaglutide from the shortage list in 2025.
Throughout this period, AI systems received substantial query volume about compounded semaglutide — its safety, its cost, its equivalence to branded product, and where to obtain it. The AI answers varied considerably in accuracy. Some systems accurately reflected FDA’s warnings. Others presented compounded semaglutide as a straightforward cost-saving alternative. Some cited sources that were either compounding pharmacy marketing or outdated information predating FDA’s removal of the shortage designation.
Novo Nordisk had direct commercial interests in monitoring these AI responses — not because correcting AI misinformation was a regulatory obligation in this context, but because accurate AI representation of the regulatory and safety situation affected branded product preference among cost-sensitive patients. The monitoring rationale was commercial, not just compliance-driven.
Physician Query Patterns for Off-Label Use in AI
Physicians use AI systems for off-label research too, and their query patterns differ from patient queries in structure but not necessarily in content. A physician asking an AI “what’s the evidence for low-dose aspirin in primary prevention” is asking an off-label application question with clinical depth. The AI answer they receive affects their prescribing behavior, not just their information comfort level.
Medical affairs teams at pharma companies have traditionally managed off-label scientific exchange through Medical Science Liaisons and congress presentations. AI systems represent an unmanaged channel where off-label evidence landscapes — positive and negative — are being synthesized for physicians who may not cross-reference the AI output against primary literature. Monitoring which off-label discussions are generating AI traffic in the physician query space is a legitimate medical affairs intelligence function.
How Eli Lilly and Novo Nordisk Monitor AI Mentions
Neither Eli Lilly nor Novo Nordisk has publicly disclosed the specifics of AI monitoring programs for their respective GLP-1 portfolios. What’s documented — through conference presentations, investor calls, and industry reporting — is that both companies have expanded digital intelligence functions significantly since 2022.
What Pharma Digital Intelligence Teams Actually Track
The major pharma companies with mature digital intelligence capabilities track several distinct data streams. Traditional social listening covers patient forums, Reddit, Twitter/X, and disease-specific communities. Clinical trial monitoring tracks investigator-initiated studies and competitive pipeline movement. Regulatory intelligence tracks FDA and EMA activities, including warning letters, label updates, and citizen petitions.
AI monitoring is the newest addition. It tracks what AI systems say about branded products, what questions drive that AI traffic, whether AI citations are pulling from accurate sources, how AI responses shift after significant events (a new clinical trial publication, an FDA safety communication, a news story), and how a company’s AI presence compares to competitors.
DrugPatentWatch, which tracks patent expiration and exclusivity data, represents the kind of structured pharmaceutical intelligence that’s being integrated with AI monitoring capabilities — understanding that a drug’s AI representation will shift significantly as it approaches patent expiration and biosimilar entry.
The Competitive Intelligence Value of AI Query Data
What patients ask AI about drugs is competitive intelligence. A spike in AI queries about a competitor’s drug’s side effects signals emerging patient concern. A pattern of questions comparing two drugs on a specific attribute — weight loss speed, injection frequency, cost — tells brand teams exactly what’s driving the competitive conversation in the patient population.
This is information that traditionally took months to surface through market research, patient surveys, and social listening synthesis. AI monitoring can surface it in near real-time because the queries happen at the moment of patient concern, not retrospectively through a survey instrument.
Brand teams that are building competitive query intelligence into AI monitoring programs — tracking not just their own drug’s AI presence but the queries that lead patients to compare drugs — have a faster read on competitive dynamics than teams relying solely on traditional market research.
Patient Sentiment in AI vs. Clinical Trial Data: The Gap That Matters
Clinical trials measure efficacy and safety under controlled conditions with defined endpoints. Patient sentiment in AI queries measures something different: how a drug actually feels to take, at scale, in the real world, without the selection bias of trial enrollment.
How AI Conversations Surface Real-World Drug Experiences
The emotional content of patient AI queries is markedly different from what surfaces in clinical records. Patients report experiences in AI conversations that they categorize as too subjective, too embarrassing, or too uncertain to bring to a physician. Cognitive effects are a consistent category: “brain fog” on statins, “feeling flat” on SSRIs, “not feeling like myself” on GLP-1 drugs. These are real experiences that don’t appear in clinical trial adverse event tables because they were never captured as adverse events — patients didn’t report them through clinical channels.
AI monitoring that captures this sentiment layer provides medical affairs and pharmacovigilance teams with a qualitative signal that complements quantitative adverse event data. It won’t replace MedWatch. It will tell you what patients are experiencing that isn’t making it to MedWatch.
Why Drug Sentiment in AI Queries Often Precedes Regulatory Action
There’s a documented lag between when patient communities begin discussing a drug safety concern and when that concern reaches formal pharmacovigilance channels. The Fen-Phen cardiac valve story was circulating in patient communities and physician networks before FDA’s 1997 withdrawal. Vioxx’s cardiovascular signal generated patient reports and anecdotal physician observations before the APPROVE trial confirmed it and the 2004 market withdrawal followed.
Social media and patient forums accelerated signal propagation after 2010. AI monitoring has the potential to accelerate it further — because patients now articulate concerns to AI systems in structured question form, which is analytically easier to process than unstructured forum posts. A pharmacovigilance team that monitors AI query patterns for concern clustering has, in theory, an earlier warning system than one relying solely on spontaneous reports.
Whether that earlier warning creates a regulatory obligation is the question that hasn’t been answered. But the companies that will be in the best position when it is answered are the ones running the monitoring now.
What Drug Misinformation in AI Means for Medical Affairs Teams
Medical affairs sits at the intersection of clinical data and commercial communication. It’s responsible for ensuring that scientific information about drugs is accurate and reaches the right audiences through appropriate channels. AI systems create a new accuracy challenge that medical affairs teams are positioned to address — but only if they’re systematically monitoring what AI is saying.
How to Detect AI Hallucinations About Your Drug
Detecting AI hallucinations about a specific drug requires a systematic querying protocol. Medical affairs teams, or the monitoring vendors they work with, need to run consistent query sets across major AI platforms — covering indication language, dosing information, contraindications, drug interactions, adverse event profiles, and mechanism of action — and evaluate the responses against current FDA-approved labeling.
The query sets need to use patient-language variations, not clinical language, because that’s what patients actually type. “Can I take Eliquis if I have a kidney problem” generates a different AI response than “apixaban dosing in chronic kidney disease,” even though they’re asking about the same clinical scenario. Both need to be tested.
When responses diverge from label language — particularly on safety-critical information — medical affairs teams have options. They can notify the AI developer through appropriate channels. They can optimize the web-based content that AI systems pull from during real-time retrieval (for systems like Perplexity with live web access). They can prioritize updating authoritative medical content on sources that AI systems cite frequently. None of these interventions is guaranteed to change AI outputs, but they address the upstream information environment.
Which AI Citation Sources Affect Drug Representation Most
For AI systems that use retrieval-augmented generation — pulling from live web sources to supplement training data — the quality of drug information in AI responses correlates directly with the quality of the sources being retrieved. FDA drug labeling databases, peer-reviewed medical literature indexed in PubMed, and authoritative medical reference sites like Medscape and UpToDate are the sources that produce the most accurate AI drug responses when they’re being retrieved.
Patient forums, health news sites with variable editorial standards, and older web content that hasn’t been updated to reflect label changes are the sources that produce the most inaccurate responses. Medical affairs teams that systematically update their company’s web presence — ensuring that official prescribing information, patient information leaflets, and disease education content are consistently authoritative and current — are, indirectly, improving the quality of AI responses about their drugs.
This is a new function for digital medical communications teams: content optimization for AI retrieval, not just for Google search ranking. The technical requirements overlap significantly, but the content standards differ. What AI systems need are unambiguous, factual, structured statements about drug characteristics — not the narrative-driven, engagement-optimized content that performs well in traditional SEO contexts.
Building an AI Drug Monitoring Program: A Practical Framework
Pharma companies at different stages of AI monitoring maturity need different starting points. The following framework addresses both early-stage and mature program development.
The Minimum Viable AI Monitoring Stack for Pharma
A minimum viable AI monitoring program for a pharmaceutical brand covers four functions:
Systematic query testing across ChatGPT, Gemini, Claude, and Perplexity, using patient-language query sets covering indication, dosing, adverse events, and drug interactions
Response accuracy auditing against current FDA labeling, with discrepancies logged and severity-rated
Query pattern tracking to identify which patient questions are driving the most AI traffic, as a proxy for emerging patient concerns
Competitive benchmarking comparing the brand’s AI representation against key competitors on the same query sets
This can be built internally using API access to major LLMs and a structured logging system, or outsourced to platforms like DrugChatter that specialize in pharmaceutical AI monitoring. The build-versus-buy decision typically favors buying for brand teams without dedicated data science resources, and building for companies with existing digital health infrastructure.
Integrating AI Monitoring With Pharmacovigilance
The integration point between AI monitoring and pharmacovigilance is signal review. AI monitoring outputs that surface patient-articulated adverse events — whether in query patterns or in AI-generated responses that reference specific symptoms — should flow into the same signal detection process that handles social media listening outputs.
This doesn’t require a new regulatory framework. It requires treating AI monitoring outputs as an additional data stream within existing signal management SOPs. Companies that have already built social media monitoring into their pharmacovigilance processes have the infrastructure to absorb AI monitoring with incremental adjustment.
The documentation requirement is the same: maintain records of what was monitored, when, what signals were identified, how they were evaluated, and what actions, if any, were taken. If AI monitoring generates a signal that doesn’t reach the threshold for a valid adverse event report but is retained in signal logs, that documentation demonstrates good-faith monitoring practice — which has regulatory value independent of any specific reporting obligation.
How to Measure ROI on AI Drug Monitoring
Return on investment for AI drug monitoring accrues through four mechanisms. The first is risk mitigation: catching inaccurate AI representations of drug safety before they generate patient harm or regulatory inquiry. The second is competitive intelligence: gaining earlier visibility into patient preference shifts and competitive narrative changes. The third is brand protection: identifying and addressing AI content that damages brand perception or creates brand confusion. The fourth is pharmacovigilance enhancement: supplementing formal adverse event surveillance with AI-derived signals that may precede formal reporting.
Quantifying the first and fourth mechanisms requires estimating the cost of the regulatory events they prevent — which is speculative but tractable using historical data on FDA warning letter costs, label update expenses, and litigation outcomes. The second and third are more directly measurable using share-of-voice metrics and brand sentiment indices. Companies that have run AI monitoring for more than twelve months have sufficient longitudinal data to construct reasonable ROI models.
The Questions Patients Ask AI That Should Be Going to Physicians
Some of what patients ask AI about drugs isn’t just a monitoring concern for pharma. It’s a patient safety concern that healthcare systems need to address.
When AI Answers Delay Necessary Medical Care
A patient who asks an AI “is chest pain a side effect of my blood pressure medication” and receives a reassuring response may delay calling their physician or seeking emergency care. A patient who asks “can I stop taking my antidepressant cold turkey” and receives an incomplete answer about discontinuation syndrome may self-taper in a way that precipitates a depressive episode.
These aren’t hypothetical scenarios. They represent patterns that AI monitoring tools can detect — not by accessing individual conversations, but by tracking query patterns that suggest patients are using AI to make consequential medical decisions without physician input. When those patterns concentrate around safety-critical decisions (medication stopping, dose adjustment, drug interactions), they’re both a pharmacovigilance signal and a healthcare systems problem.
What “Ask Your Doctor” Actually Means When Patients Don’t Ask Their Doctors
Direct-to-consumer pharmaceutical advertising has used the “ask your doctor” construct for decades. The construct assumes that patients, once informed, will bring their questions to their physicians. The AI conversation data suggests that assumption has always been partially false — and is becoming more so as AI systems provide sufficiently satisfying answers that patients don’t feel the physician conversation is necessary.
This creates a feedback problem. Patients get AI answers that seem complete. They don’t ask their doctors. Their doctors don’t know they’re asking. Patient behavior patterns that would, if visible to physicians, prompt a medication review or safety conversation instead remain invisible in the AI channel.
Pharma companies that have invested in physician education about AI-mediated patient information-seeking are creating a partial corrective. Medical affairs teams that brief physicians on what patients are asking AI about specific drugs — using aggregate monitoring data — are closing some of that loop. The physician who knows that their buprenorphine patients are frequently asking AI about intoxication on prescribed doses is in a better position to open that conversation proactively.
LLM Search Optimization for Pharmaceutical Brands
SEO for AI search differs from traditional Google SEO in ways that pharmaceutical digital teams need to understand.
How Pharma Content Performs in AI Search vs. Google Search
Google Search ranks pages based on a combination of authority signals, content relevance, and user behavior data. AI systems rank information based on how prominently and how often it appears in training data, how authoritative the source is perceived to be, and — for retrieval-augmented systems — how well the content answers the specific query structure.
Pharmaceutical content that performs well in Google Search doesn’t automatically perform well in AI search. Long-form, narrative-driven patient education content may rank well in Google for target keywords but be underutilized by AI systems that prefer concise, factual, structured responses. A drug’s official prescribing information — dense, structured, comprehensive — may actually perform better as an AI knowledge source than the polished patient website written to rank for consumer queries.
The implication is that pharmaceutical digital teams need two parallel content strategies: one optimized for traditional search, and one optimized to serve as accurate AI training and retrieval material. The second strategy prioritizes factual density, source authority, and structural clarity over narrative engagement.
Structured Data and Schema Markup for Drug Information in AI
Schema markup — structured data that tells search engines and AI systems what a piece of content contains — has specific relevance for pharmaceutical content. MedicalWebPage, Drug, and MedicalCondition schema types allow drug information content to self-identify as pharmacologically relevant and structurally tagged. AI systems with retrieval capabilities can use that structured data to locate authoritative drug information more reliably.
Pharmaceutical digital teams that have implemented comprehensive schema markup on their branded and disease-education websites are, in effect, improving their AI search visibility. This is one of the few LLM search optimization interventions that’s both technically tractable and directly within a pharma company’s control.
Key Takeaways
Patients ask AI about drugs in ways they don’t ask physicians — covering stigma, cost, compliance behavior, and side effect concerns they perceive as too sensitive for clinical conversation. These queries are pharmacovigilance-relevant and largely invisible to current surveillance systems.
AI hallucinations about drug safety, dosing, and contraindications occur at rates that would be clinically unacceptable from human sources. Monitoring which inaccuracies circulate in AI responses is both a brand protection and a patient safety function.
The GLP-1 category demonstrates that AI brand representation can diverge significantly from clinical reality — with Ozempic dominating AI responses over Wegovy even where Wegovy is the clinically appropriate product. AI share-of-voice monitoring is a measurable competitive intelligence function.
FDA has not issued guidance specific to AI-generated drug information or its pharmacovigilance implications. Companies building documentation practices around AI monitoring now are ahead of regulatory requirements that will eventually emerge.
Off-label discussions, compounding alternatives, and generic substitution recommendations all generate significant AI query traffic that brand and medical affairs teams need to monitor systematically.
AI monitoring ROI accrues through risk mitigation, competitive intelligence, brand protection, and pharmacovigilance enhancement — all measurable with appropriate program design and longitudinal tracking.
LLM search optimization requires a different content strategy than traditional SEO, prioritizing factual density and structured data over narrative engagement. Pharma digital teams need both in parallel.
Platforms like DrugChatter are purpose-built for pharmaceutical AI monitoring, offering systematic query tracking, response accuracy auditing, and competitive benchmarking that exceeds what internal builds can deliver without dedicated data science resources.
FAQ
What kinds of drug questions do patients ask AI that they don’t ask their doctors?
Patients use AI to ask drug questions that feel stigmatizing, financially awkward, or admissive of non-compliance. Common categories include questions about drug interactions with alcohol or recreational substances, questions about skipped doses or self-adjusted dosing, questions about off-label uses they’ve read about, and questions about whether a drug is affecting them emotionally or cognitively in ways they consider too subjective to raise in a clinical appointment. These questions contain real adverse event signals and real behavioral data that don’t reach formal pharmacovigilance channels.
Can AI hallucinations about drugs create liability for pharmaceutical companies?
The liability question is unresolved but live. If an AI system consistently misrepresents a drug’s safety profile and patients make decisions based on that misrepresentation, questions arise about whether the drug manufacturer has a duty to correct publicly accessible misinformation about their product. FDA’s existing guidance on correcting internet-based drug misinformation predates LLMs and doesn’t directly address AI-generated content. Companies that are monitoring AI representations of their drugs and documenting their responses to inaccuracies are building a defensible good-faith record against future regulatory or legal scrutiny.
How do pharmaceutical companies measure AI share of voice for their drugs?
AI share-of-voice measurement requires systematically querying major AI platforms — ChatGPT, Gemini, Claude, Perplexity — with patient-facing question sets that simulate real consumer queries. The analysis captures which brands appear in AI responses, in what context, with what sentiment, and how often a brand appears relative to competitors on the same query sets. Longitudinal tracking then shows how AI representation shifts over time as training data updates, news cycles change, or regulatory events alter the information environment. Specialized platforms like DrugChatter automate this process for pharmaceutical brands.
Do AI systems recommend generic drugs over branded drugs more often?
The pattern is drug-class dependent. For established small molecules with clear generic equivalence — statins, common antibiotics, ACE inhibitors — AI systems do frequently volunteer that generics are available and therapeutically equivalent. The issue arises in categories where the branded-versus-generic question is clinically nuanced: narrow therapeutic index drugs, extended-release formulations, and biologics with biosimilar alternatives. AI systems tend to flatten clinical nuance in these categories, presenting generic or biosimilar equivalence as simpler than clinical guidelines actually support. For brands like Humira, levothyroxine formulations, and extended-release psychiatric medications, monitoring AI responses on the generic substitution question is both commercially and clinically relevant.
What is the regulatory status of using AI monitoring data for pharmacovigilance?
FDA has not issued specific guidance on AI monitoring data as a pharmacovigilance source. Its existing framework for social media-derived adverse event reports applies when AI conversations meet the four elements for a valid case — identifiable patient, suspect drug, adverse event, identifiable reporter — which AI-generated conversation data rarely does in practice. What AI monitoring can reliably contribute is aggregate signal detection: identifying query patterns that suggest patient populations are experiencing symptoms worth investigating through conventional surveillance channels. Companies are best positioned to treat AI monitoring outputs as an additional signal detection layer within existing pharmacovigilance SOPs, with appropriate documentation of monitoring activities and signal evaluation decisions.
Get sharp analysis on AI-generated drug information, off-label curiosity, pharmacovigilance blind spots, and the shifting intersection of pharma, search, and large language models. No fluff. Just the signals that matter.